
군집화 - 비지도학습
- 데이터를 클러스터 (cluster, 유사한 아이템의 그룹)로 자동 분리하는 비지도 학습이다.(unsupervised learning)
- 군집화는 데이터 안에서 발견되는 자연스런 그룹에 대한 통찰력을 제공
- 클러스터 안에 있는 아이템들은 서로 비슷해야 하지만 클러스터 밖에 있는 아이템과는 아주 달라야 한다.
군집화 활용 분야
- 생물학 분야 : 식물계통학에서 다수의 속성을 공유하는 종과 속의 분류
- 유전 데이터의 유사성 분석
- 의료 분야에서는 단층촬영으로 클러스터 분석을 사용하여 3차원 이미지에서 여러 유형의 조직을 구별
- 비지니스에서는 소비자 집단을 여러 시장으로 분할하거나 소비자를 분류하여 각 소비자 그룹별 마케팅 믹스 전략을 사용
- 사회관계망 분석에서는 여러 그룹의 커미니티를 인식하는데 사용
- 알고 있는 클러스터 밖의 사용 패턴을 찾아 무단 네트워크 침입과 같은 이상 행동 탐지
k-means algorithm
- n개의 데이터를 k개의 클러스터 중 하나에 할당하는데 이때 k는 사전에 결정되는 수(k : 군집의 개수)
 |
 |
 |
k값 찾기
k 값을 구하는 공식
n = 100
k = sqrt(n/2)
k-means의 한계점
- k값은 직접 입력해야 한다.
- 이상치에 민감하다. 그래서 표준화, 정규화 작업을 생각하자
k값(n_clusters)가 어떤값이 가장 적당한지 찾기
| from sklearn.cluster import KMeans import pandas as pd import numpy as np import matplotlib.pyplot as plt from matplotlib import font_manager, rc font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name() rc('font', family=font_name) |
|
|
academy = pd.read_csv("c:/pypy/academy.csv",encoding="CP949") academy.columns model = KMeans(n_clusters=4) model.fit(academy.iloc[:,2:4]) model.labels_ model.predict(academy.iloc[:,2:4]) model.cluster_centers_ |
 |
|
colormap = np.array(['red', 'blue', 'black','yellow']) plt.scatter(academy.iloc[:,2], academy.iloc[:,3], c=colormap[model.labels_], s=30) plt.title('K Mean Classification') |
 |
|
centers = pd.DataFrame(model.cluster_centers_) plt.scatter(centers.iloc[:,0],centers.iloc[:,1],s=50,marker='D',c='g') plt.show() |
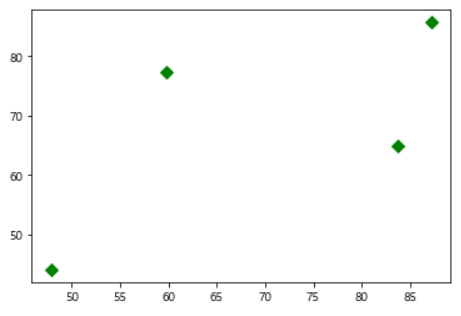 |
|
ks = range(1,10) inertias = [] # model.inertia_ : 응집도의 계산정도 for k in ks: model = KMeans(n_clusters=k) model.fit(academy.iloc[:,2:4]) inertias.append(model.inertia_) |
|
|
plt.plot(ks, inertias, '-o') plt.xlabel('number of clusters, k') plt.ylabel('inertia') plt.xticks(ks) plt.show() |
 |
inertia value는 군집화가 된 후에 각 중심점에서 군집의 데이터 간의 거리를 합산한 것으로 군집의 응집도를 나타내는 값이다.
이값이 작으면 작을수록 응집도가 높게 군집화가 잘되었다고 평가한다.
즉 위 그림에선 4,5,6정도에서 고르면 좋음
R을 이용한 군집화
| # 데이터셋 만들기 c <- c(3,4,1,5,7,9,5,4,6,8,4,5,9,8,7,8,6,7,2,1) |
 |
|
# k-means가 있는 라이브러리 불러오기 library(stats) |
|
|
# k-means 사용 및 그래프로 표현 |
 |
|
# 클러스터 정보 확인 km$cluster |
 |
|
# 센터 정보 확인 (좌표로 확인) km$centers plot(km$centers) |
  |
|
# 1번군집/2번군집 좌표 확인 cbind(data, km$cluster) |
 |
|
# 센터 좌표만 확인 plot(km$centers, pch=4, bg=km$centers, xlim=range(0:10), ylime=range(0:10),col=km$cluster) par(new=T) |
 |
|
### 다른 방법 plot(data,col=km$cluster, xlim=range(0:10),ylime=range(0:10)) |
 |
|
# 센터좌표 (위의 센터 좌표를 그대로 옮긴것 뿐) points(km$centers,pch=4) |
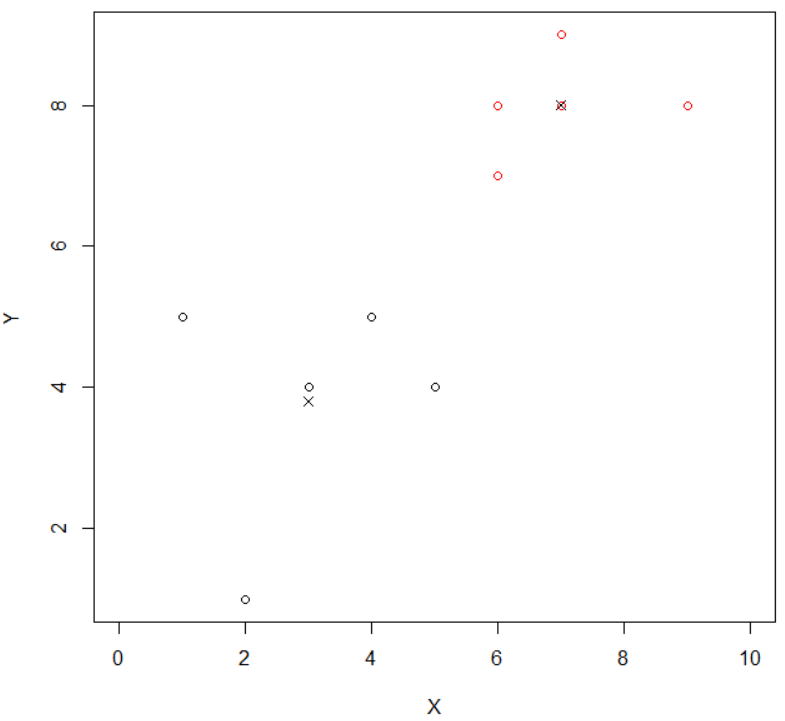 |
| # 데이터 불러오기 academy <- read.csv("C:/data/academy.csv") |
|
|
academy2<-academy[,c(3,4)] km <- kmeans(academy2,3) |
|
|
# 점수 분포 plot(academy2) |
 |
|
# 중간값 points(km$centers,pch=4) |
 |
|
# 군집화에 특화된 그래프 그리기 라이브러리 install.packages("factoextra") library(factoextra) |
|
| # 군집화 그래프 그리기 1 fviz_cluster(km, data=academy2) |
 |
|
# 군집화 그래프 그리기 2 |
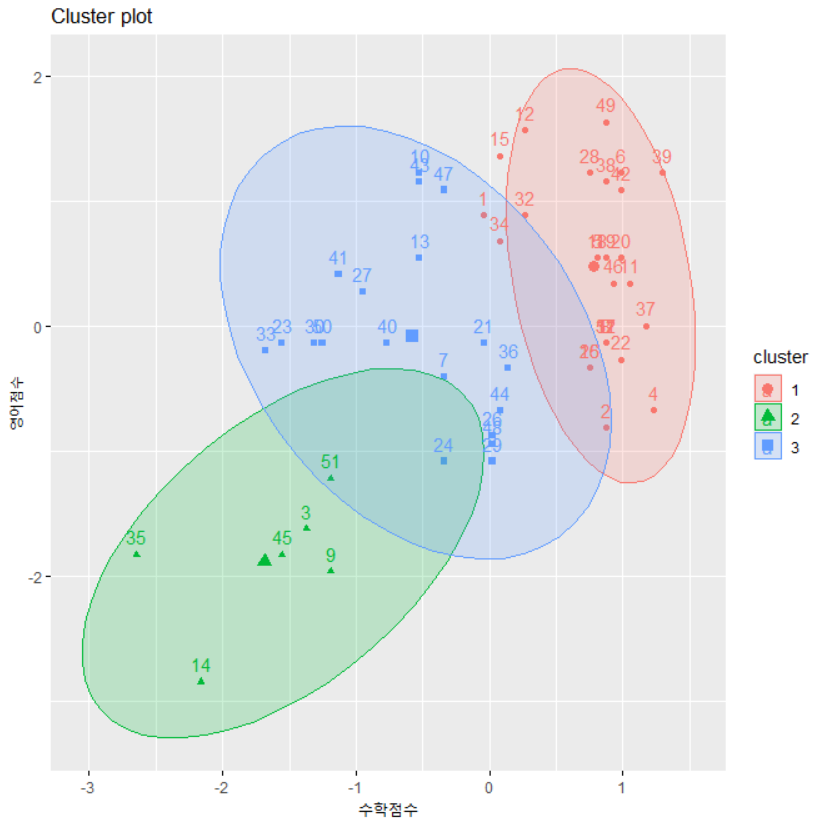 |
|
# 인덱스 번호 같이보기 cbind(academy2,km$cluster) |
 |
| # 데이터 불러오기 iris <- read.csv("C:/data/iris.csv") |
 |
|
iris2<-iris[,c(1,2,3,4)] |
 |
| # 군집화 그래프 그리기 fviz_cluster(km, data=iris2) |
 |
파이썬을 이용한 군집화
|
# 라이브러리 불러오기 |
|
|
# 데이터 불러오기 iris = pd.read_csv("c:\data\iris.csv") |
 |
| plt.figure(figsize=(14,7)) plt.subplot(1, 2, 1) plt.scatter(iris.SepalLength, iris.SepalWidth, s=40) plt.title('Sepal') |
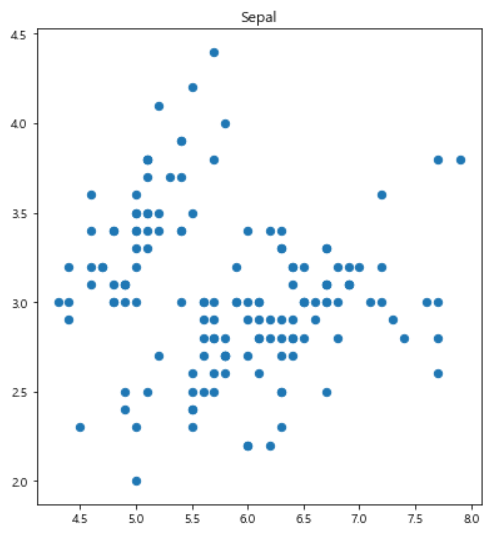 |
|
plt.figure(figsize=(14,7)) |
 |
|
# n_clusters=3 : 3개로 군집 model = KMeans(n_clusters=3) model.fit(iris.iloc[:,0:4]) model.labels_ |
 |
|
plt.figure(figsize=(14,7)) |
 |
'인공지능 > 머신러닝' 카테고리의 다른 글
| 회귀분석 (0) | 2020.06.11 |
|---|---|
| 평균, 분산, 상관분석 (0) | 2020.06.09 |
| 연관규칙 / 연관성 분석 (0) | 2020.05.28 |
| 와인품질데이터 - 의사결정트리 / 랜덤 포레스트 (0) | 2020.05.27 |
| 앙상블(Ensemble), 랜덤 포레스트(Random Forest) (0) | 2020.05.27 |