
와인품질 데이터 컬럼 설명
fixed acidity : 고정 산도
volatile acidity : 휘발성 산도
citric acid : 시트르산
residual sugar : 잔류 설탕
chlorides : 염화물
free sulfur dioxide : 자유 이산화황
total sulfur dioxide : 총 이산화황
density : 밀도
pH : pH
sulphates : 황산염
alcohol : 알코올
quality : 품질 # 종속변수
1. 의사결정트리 (파이썬)
|
# 라이브러리 및 데이터 불러오기 |
 |
|
# 종속변수 / 입력변수 나누기 x = wine.iloc[:,0:11] y = wine['quality'] |
 |
|
# 모델 학습 |
 |
| # 모델 예측 y_pred = model.predict(x) |
 |
| # 정확도 확인 from sklearn.metrics import accuracy_score accuracy_score(y,y_pred) |
 |
| model.classes_ | |
| # 그래프 설정 dot_data = export_graphviz(model, out_file=None, feature_names=x.columns, class_names=['q3','q4','q5','q6','q7','q8','q9'], filled=True, rounded=True, special_characters=True) |
|
| # 그래프 그리기 graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png()) |
 |
2. 랜덤포레스트 (파이썬)
|
# 라이브러리 및 데이터 불러오기 |
 |
|
# 종속변수 / 입력변수 나누기 x = wine.iloc[:,0:11] y = wine['quality'] |
 |
|
# 라이브러리 불러오기 |
|
|
# 출력할때 warning 안뜨게하기 import warnings warnings.filterwarnings('ignore') warnings.filterwarnings('default') |
|
|
# 모델 학습 model.fit(x,y) |
 |
|
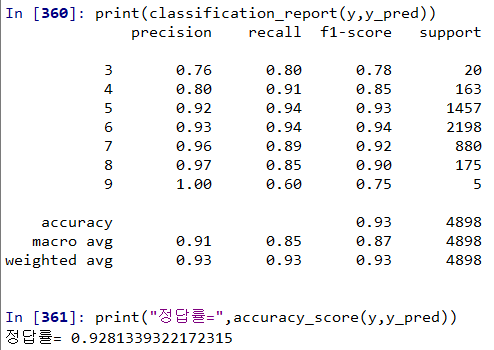
# 모델 예측 및 정확도 확인 |
 |
|
# 모델안에 몇번째거를 그릴건지를 넣어야한다. estimator = model.estimators_[0] dot_data = export_graphviz(estimator, out_file=None, feature_names=x.columns, class_names=['q3','q4','q5','q6','q7','q8','q9'], filled=True, rounded=True, special_characters=True) |
|
| # 그래프 그리기 graph = pydotplus.graph_from_dot_data(dot_data) |
'인공지능 > 머신러닝' 카테고리의 다른 글
| 군집화 (0) | 2020.06.08 |
|---|---|
| 연관규칙 / 연관성 분석 (0) | 2020.05.28 |
| 앙상블(Ensemble), 랜덤 포레스트(Random Forest) (0) | 2020.05.27 |
| 의사결정트리 시각화 (0) | 2020.05.23 |
| 의사결정트리를 이용한 타이타닉 데이터셋 분석 (0) | 2020.05.19 |