
타이타닉 데이터셋 (titanic.csv)

- survived : 목표변수, 종속변수, 생존여부(0:사망, 1:생존)
- pclass : 좌석 등급
- name : 탑승객 이름
- gender : 성별
- age : 나이
- sibsp : 함께 탑승한 형제수
- parch : 함께 탑승한 부모수
- ticket : 티켓 번호
- fare : 탑승권 가격
- cabin : 선실 번호
- embarked : 탑승 승착장
R 로 분석하기
|
# 데이터 불러오기 및 데이터 정보 확인 |
 |
| # 목표변수 Factor 형으로 바꿔주기 titanic$survived <- as.factor(titanic$survived) |
 |
|
# 입력변수 중에 빈문자열이 있으면 안돌아간다. (NA는 상관없음) sapply(titanic, function(x)sum(x=='')) |
 |
|
# 빈문자열 삭제 |
 |
|
# 컬럼별 NA의 개수 세기 sapply(titanic, function(x)sum(is.na(x))) |
 |
|
# NA가 들어간 데이터를 버리긴 아까우니까 NA대신 중앙값을 넣자 titanic[is.na(titanic$age),'age'] <- median(titanic$age, na.rm=T) |
 |
|
# 이름, 티켓번호, 선실번호 빼고 모델 만들기 titanic <- titanic[,c(-3,-8,-10)] model <- C5.0(survived~.,data=titanic, trale=20) summary(model) |
  |
| # 모델 그래프로 그리기 plot(model) |
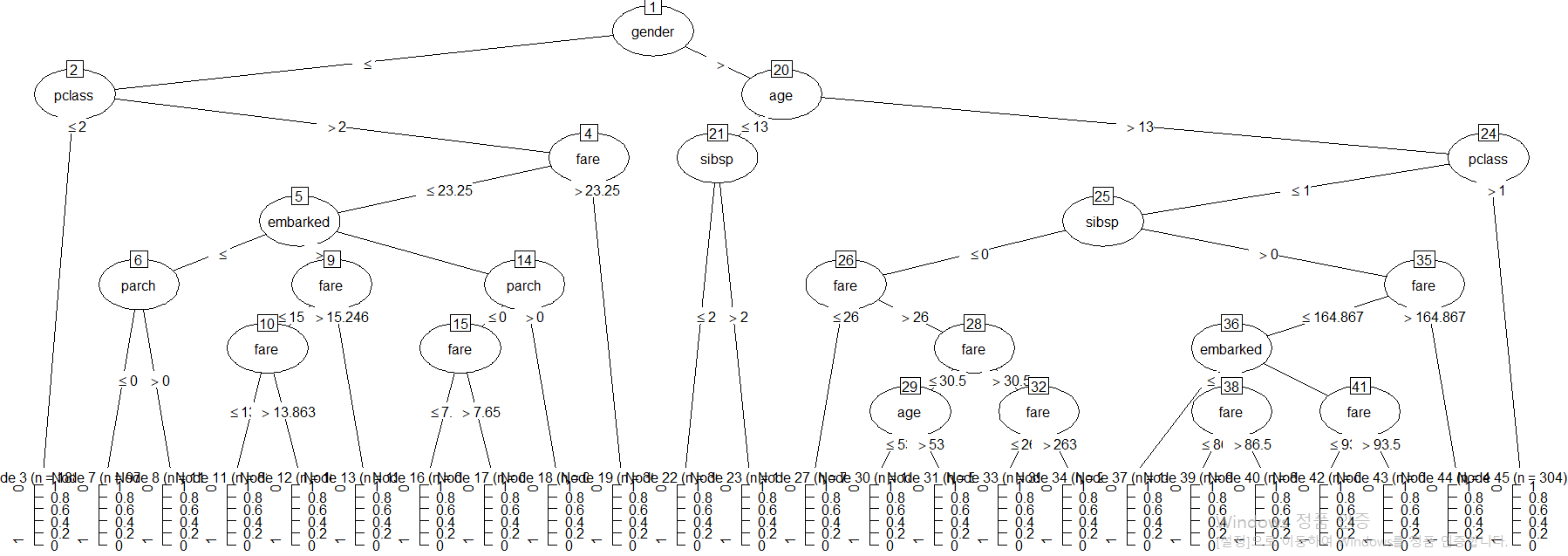 |
파이썬으로 분석하기
|
# 데이터 불러오기 및 데이터 정보 확인 import pandas as pd titanic = pd.read_csv("C:/data/titanic.csv") titanic.info() titanic.head() |
  |
|
sklearn은 문자형말고 보편적 수치형으로 바꿔주어야한다. ====> 원핫 인코딩해주자 # 0, 1로 변경작업을 해야한다. # one-hot encoding # 여성 0, 남성 1 titanic["gender"] = titanic.gender.map({"female":0, "male":1}) |
 |
|
# 개수세기 from collections import Counter Counter(titanic["gender"]) |
 |
|
# 목표변수 : survived( 0 : 사망, 1 : 생존) Counter(titanic["survived"]) |
 |
|
# Null체크하기 titanic.isnull() |
 |
|
# 열별로 Null값 체크하기 (빈문자열도 포함됨) # age의 Null값 체크하기 titanic["age"].isnull().sum() titanic.isnull().sum()['age'] # 전체 null갯수 확인 titanic.isnull().sum().sum() |
   |
|
# age의 NaN값만 뽑아내기 # age의 NaN값을 중앙값으로 대체 titanic.age.fillna(titanic.age.median(), inplace=True) |
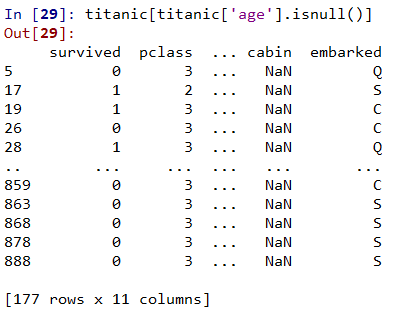 |
|
# pd.get_dummies() : 원핫인코딩을 자연스럽게 만들어줌 embarked_dummies = pd.get_dummies(titanic.embarked, prefix="embarked") |
 |
|
# titanic 데이터셋과 embarked_dummies데이터셋 붙이기 titanic = pd.concat([titanic,embarked_dummies],axis=1) titanic |
 |
|
# 학습시킬 특정컬럼 뽑아내기 feature_col = ['pclass','age','gender','embarked_Q','embarked_S'] titanic[feature_col] |
 |
|
from sklearn.tree import DecisionTreeClassifier # criterion="entropy" : 엔트로피를 사용하겠다. # max_depth = 3 : 질문수 3개 제한 # 모델 정의 model = DecisionTreeClassifier(criterion="entropy", max_depth = 3) # 모델 학습 model.fit(x,y) # 중심적으로 사용했던 컬럼 보기 pd.DataFrame({'feature': feature_col, 'importance' : model.feature_importances_}) |
 |
'인공지능 > 머신러닝' 카테고리의 다른 글
| 앙상블(Ensemble), 랜덤 포레스트(Random Forest) (0) | 2020.05.27 |
|---|---|
| 의사결정트리 시각화 (0) | 2020.05.23 |
| 의사결정트리 (0) | 2020.05.18 |
| 머신러닝 연습 ① - 영화평 긍정/부정 리뷰 예측 (0) | 2020.05.14 |
| NLTK 자연어 처리 패키지 사용 (0) | 2020.05.14 |