
연관규칙 ,연관성분석 (association analaysis) - 비지도 학습
- 대량의 데이터에 숨겨진 항목간의 연관규칙을 찾아내는 기법으로서 다른말로 장바구니 분석(market basket analysis)이라고도 한다.
- 실제 연관성 분석은 월마트, 아마존 등 여러기업에서 다양한 마케팅 활동에 활용하고 있으며 더 나아가 사회 네트워크 분석에도 활용할 수 있다.
장점
- 대규모 거래 데이터에 대해 작업을 할 수 있다.
- 이해하기 쉬운 규칙을 생성해준다.
- 데이터마이닝과 데이터 베이스에서 예상치 못한 지식을 발굴하는데 유용하다.
단점
- 작은 데이터셋에는 그다지 유용하지 않다
- 진정한 통찰력과 상식을 분리하기 위한 노력이 필요하다.
지지도(support)
- 전체 거래중 연관성 규칙을 구성하는 항목들이 포함된 거래의 비율
|
항목에 대한 거래수 |
신뢰도(confidence)
- 조건이 발생했을때 동시에 일어날 확률을 의미하며 신뢰도가 1에 가까울수록 의미있는 연관성을 가지고 있다.
- {조건} -> {결과}
|
support(x,y) |
|
조건과 결과 항목을 동시에 포함하는 거래수 |
예)
| 거래번호 | 구매물품 |
| 1 | 우유, 버터, 시리얼 |
| 2 | 우유, 시리얼 |
| 3 | 우유, 빵 |
| 4 | 버터, 맥주, 오징어 |
S(우유 -> 시리얼) : 우유와 시리얼을 동시에 구매할 확률
{우유,시리얼} 포함한 거래수/ 전체거래수
50%(2/4)
C(우유 -> 시리얼) : P(시리얼|우유)
우유를 구매할때 시리얼도 같이 구매할 조건부확률
{우유,시리얼} 포함한 거래수/ {우유}거래수
2/3
C(시리얼 -> 우유) : P(우유|시리얼)
시리얼를 구매할때 우유도 같이 구매할 조건부확률
{우유,시리얼} 포함한 거래수/ {시리얼}거래수
100%(2/2)
우유 -> 시리얼 (지지도 : 50% 신뢰도 : 66%)
시리얼 -> 우유 (지지도 : 50% 신뢰도 : 100%)
향상도(lift)
- 지지도와 신뢰도를 동시에 고려한다.
- 향상도가 1이 나오면 연관성이 없다.
- 향상도가 1이상이면 연관성이 있다.
- 향상도 값이 1인 경우 조건과 결과는 우연에 의한 관계라고 보며 1보다 클수록 우연이 아닌 의미있는 연관성을 가진 규칙이라고 해석하면 된다.
신뢰도(시리얼 -> 우유)
lift(시리얼, 우유) = ------------------------------------ = (2/2)/(3/4) = 1.3333
지지도(우유)
지지도(시리얼 -> 우유)
lift(시리얼, 우유) = ------------------------------------ = 1.3333
지지도(우유) * 지지도(시리얼)
lift(시리얼, 버터) = (1/2)/(2/4) = 1
연관성 분석 (R)
|
# 라이브러리 설치 및 불러오기 |
|
|
# 데이터셋 만들기 buylist <- list(c("우유","버터","시리얼"), c("우유","시리얼"), c("우유","빵"), c("버터","맥주","오징어")) |
 |
|
# 트랜잭션 데이터 형변환 (리스트 -> 트랜잭션데이터) buylist <- as(buylist,"transactions") buylist |
 # 거래 4건 / 거래항목 6건 |
|
# 트랜잭션 데이터를 확인하는 방법 inspect(buylist) |
 |
|
# 연관성 찾기 apriori(buylist) |
 |
|
# conf=0.5 : 신뢰도 0.5이상 buyresult <- apriori(buylist,parameter=list(conf=0.5)) |
 # minlen, maxlen : 항목 조합개수 한정 |
|
# 조합보기 inspect(buyresult[1:10]) |
 # lhs(left hand side) 조건(원인) -> rhs(right hand side) 결과 |
|
# 제한해서 보기 inspect(subset(buyresult, subset=support>=0.5)) |
 |
| inspect(subset(buyresult, subset=lift>1)) |  |
| inspect(subset(buyresult, subset=lhs %in% c("버터","시리얼"))) |  |
| # 버터와 시리얼만 있어야함 inspect(subset(buyresult, subset=lhs %ain% c("버터","시리얼"))) |
 |
| # 버터와 시리얼이 있는건 다찾기 inspect(subset(buyresult, subset=lhs %oin% c("버터","시리얼"))) |
 |
| inspect(subset(buyresult, subset=lhs %pin% "우")) |  |
|
# 빈도수 itemFrequencyPlot(buylist) |
 |
|
# 지지도가 0.5이상인거 빈도수 itemFrequencyPlot(buylist,support=0.5) |
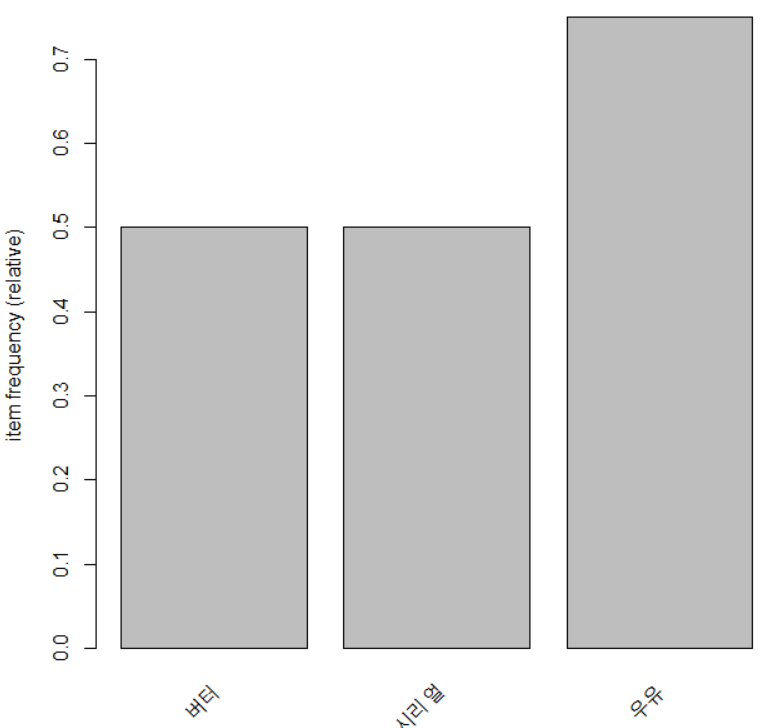 |
|
# 연관성 그래프 그리기 |
 |
|
plot(buyresult,method="grouped") |
 |
|
subresult <- subset(buyresult, subset=lift>1) # 정렬하기 buyorder <- sort(subresult,by=c("support","lift","confidence")) inspect(buyorder) plot(buyorder,method = "paraco") |
 |
| plot(buyorder[2],method = "paraco") |  |
|
# 바로 트랜잭션으로 읽어들이기 groceries <- read.transactions("C:/pypy/groceries.csv",sep=",") str(groceries) summary(groceries) inspect(groceries[1:5]) |
 |
| # 빈도수 체크 itemFrequencyPlot(groceries,topN=10) |
 |
|
# 연관성 분석 그래프로 그리기 |
 |
|
# 연관성 분석 그래프로 그리기 |
 |
|
# 베리류만 저장하기 berryrules <- subset(groresult,subset=lhs %in% "berries") inspect(berryrules) write(berryrules,file = "C:/data/berryrules.csv",sep=",",quote=F, row.names=FALSE) data <- read.csv("C:/data/berryrules.csv") data berry_df <- as(berryrules,"data.frame") berry_df |
 |
연관성 분석 (파이썬)
| # 라이브러리 설치 <아나콘다 프롬프트> pip install --no-binary :all: mlxtend |
|
|
# 라이브러리 불러오기 import pandas as pd from mlxtend.preprocessing import TransactionEncoder from mlxtend.frequent_patterns import apriori |
|
|
# 데이터셋 만들기 dataset = [["우유","버터","시리얼"], ["우유","시리얼"], ["우유","빵"], ["버터","맥주","오징어"]] dataset |
 |
|
# 데이터 형태 가공하기 (트랜젝션 모양으로) te = TransactionEncoder() te_ary = te.fit(dataset).transform(dataset) df = pd.DataFrame(te_ary,columns=te.columns_) df |
 |
|
# 연관규칙 f = apriori(df, min_support=0.5, use_colnames=True) f |
 |
|
# 연관규칙 from mlxtend.frequent_patterns import association_rules association_rules(f,metric="confidence") |
 |
|
# 데이터셋 불러오기 dataset = pd.read_csv("C:/data/building.csv") dataset |
 |
|
# 데이터셋 정제작업 dataset = dataset.fillna(0) del dataset['Unnamed: 0'] dataset |
 |
|
# 컬럼이름 변경 col = dataset.columns col dataset.columns = ["a","b","c","d","e","f","g","h","i","j","k","l"] |
 |
|
# 데이터 형태 가공하기 (트랜젝션 모양으로) !!!이상한점!!! 컬럼이름이 숫자로 되어있으면 컬럼이 몇개 삭제된다. !!!알아냄!!! 숫자도 한글자로 변해서 10,11,12가 사라짐 te = TransactionEncoder() te_ary = te.fit(dataset).transform(dataset) te_ary df = pd.DataFrame(te_ary,columns=te.columns_) df.info() |
 |
|
# 연관규칙 f = apriori(df, min_support=0.01, use_colnames=True) f |
 |
|
# 연관규칙 from mlxtend.frequent_patterns import association_rules association_rules(f,metric="confidence",min_threshold=0.3) |
 |
| # 라이브러리 불러오기 import re |
|
|
# 데이터 불러오기 및 구조 확인 |
 |
|
dataset = [] for i in range(len(lines)): lines[i] = re.sub('\\n','',lines[i]) dataset.append(lines[i].split(',')) dataset |
 |
|
te = TransactionEncoder() df = pd.DataFrame(te_ary,columns=te.columns_) df |
 |
|
f = apriori(df, min_support=0.1, use_colnames=True) |
 |
'인공지능 > 머신러닝' 카테고리의 다른 글
| 평균, 분산, 상관분석 (0) | 2020.06.09 |
|---|---|
| 군집화 (0) | 2020.06.08 |
| 와인품질데이터 - 의사결정트리 / 랜덤 포레스트 (0) | 2020.05.27 |
| 앙상블(Ensemble), 랜덤 포레스트(Random Forest) (0) | 2020.05.27 |
| 의사결정트리 시각화 (0) | 2020.05.23 |