
회귀분석(regression)
- 인과관계를 분석하는 방법
인과관계
- 어떤 변수가 어떤 변수에게 어떤 영향을 주는지를 판단
인과관계의 조건
1. x가 변할때 y도 변한다.
- 교육연수 -> 생활만족도
2. 시간적으로 선행되어야 한다.
- 교육연수가 먼저 선행되어야 한다.
3. 외생변수를 통제(다른 요인을 통제하고 인과관계를 분석)
- 교육연수 -> 생활만족도
- 다른 요인 (성별, 직업, 거주지, 근무연수, ...)
상관관계
- 변수와 변수가 어떤 연관이 있는지 방향성을 나타내다.
종속변수, 목표변수
- 영향을 받는 변수
독립변수, 설명변수
- 영향을 주는 변수
예 )
| 독립변수 | 종속변수 |
| 담배량 | 폐암 |
| 배기량 | 연료소비량 |
| 광고비 | 매출액 |
| 수학 | 인공지능 전문가 -> 돈 -> 생활만족도 -> 자동차 판매량 -> 연료소비량 |
독립변수의 수
1개일때 : 단순회귀분석
2개이상일때 : 다중회귀분석
회귀선 그리기
1. 산점도를 그려보는게 좋다.
- x가 커지면 y도 커진다(선형)
- x가 커지면 y는 작아진다(선형)
- x가 커지면서 y커진다가 작아진다(비선형)
2. 모델의 선을 그려본다. (추세선, 직선의 방정식)
y = ax +b
- 최소제곱법을 이용해서 선을 그린다.(오차의 제곱이 최소화된 추세선)
- 이 직선은 평균을 지난다.
- ordinary least squared(ols)
- y : 종속변수, x : 독립변수, a : 회귀계수(기울기, y증가량/x증가량, 델타y/델타x), b : 절편(y시작점, x가 0일때 y값)
- 오차가 최소로 만드는거 최소제곱법
|
y = ax + b 기울기(a) = ∑(∑(x-x평균)*∑(y-y평균)) / ∑(x-x평균)^2 = x,y의 공분산 / x의 분산 = cov(x,y) / var(x) 절편(b) = y의 평균 - 기울기 * x의 평균 |
회귀분석을 이용한 몸무게 예측 (R)
키가 185일때 몸무게는?
|
# 데이터셋 만들기 |
|
| # 산점도 그리기 plot(height, weight) |
 |
|
cov(height,weight)
a = cov(height,weight) / var(height) |
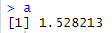 |
|
# 절편 y = mean(weight) x = mean(height) b = y - a * x |
 |
|
# y값 예측 y_hat <- a * 182 + b y_hat |
 |
|
# 회귀식 l <- lm(weight~height) |
 # (Intercept) : 절편 |
|
# 회귀모델 방정식의 기울기, 절편 보기 coef(l) |
 |
|
# 회귀분석 도출에 사용된 독립변수를 가지고 산출한 예측값# height값을 모델에 넣었을때 나온 값 리턴 fitted(l) |
 |
|
# fitted와 실제 종속변수 값과의 차이(잔차) residuals(l) |
 |
|
# 잔차제곱 합 - 모델평가시 사용(작을수록 좋은 모델) deviance(l) |
 |
|
!!! 중요 !!! |

# 주로 봐야할 부분 (회귀모델을 채택할 기준) Std. Error : 표준오차 (기울기의 오류가 중요) Pr(>|t|) : 0.05보다 작으면 좋은모델 / 0.05보다 큰 모델 R-squared : 결정계수 |
|
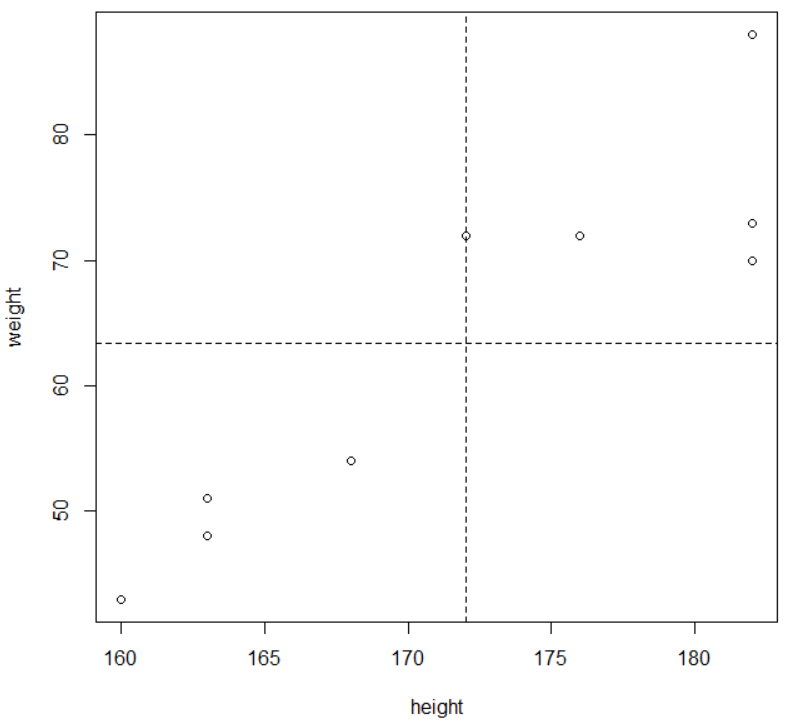
### 그래프 그리기 plot(height, weight)
|
 |
|
# 중심선 그리기 abline(h=mean(weight),lty=2) abline(v=mean(height),lty=2)
|
 |
|
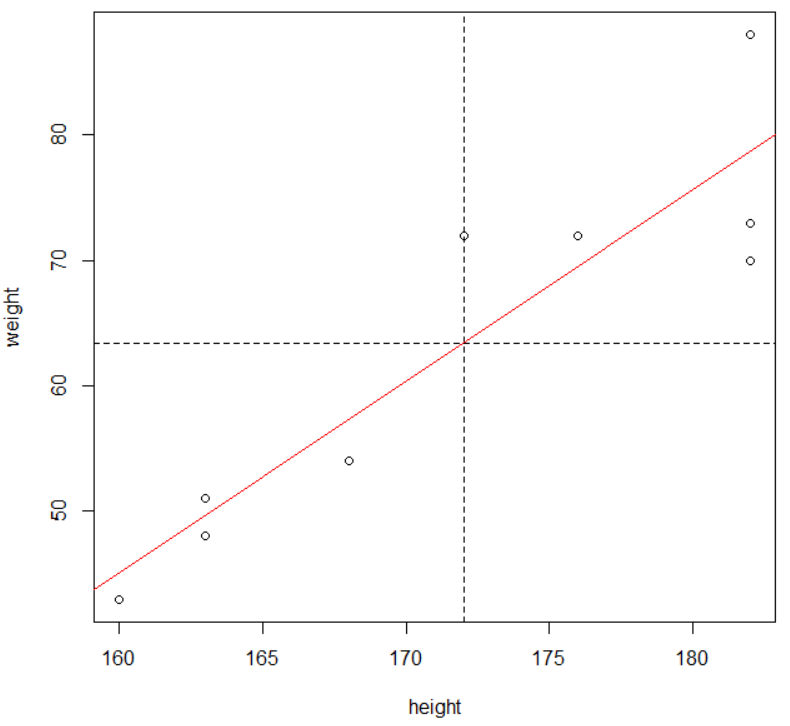
# 회귀선 그리기 abline(l,col="red")
|
 |
모델의 정확도 확인 (결정계수)
- 모델이 얼마나 정확한지에 대한 여부는 결정계수(R-squared)를 통해 확인한다.
- 0~1사이의 값을 가지며 1에 가까울수록 회귀선에 데이터들이 밀집되어 있다는 것을 의미한다.
- 예를 들어 결정계수 0.95는 도출된 회귀모델식으로 종속변수의 95%를 설명할 수 있다는 의미이다.
p-value
- 도출한 분석 모델의 결과가 통계적으로 의미가 있는지 없는지에 대한 판정을 객관적인 지표로 결정해야 한다.
- 통계의 유의성을 대표하는 지표가 p-value이다.
가설검정
- 어떤 주장이 맞는지 틀리지 검정을 통해서 합리적인 의사결정을 한다.
귀무가설 (null hypothesis, Ho)
- 현재 지속되어 있는 가설 (영가설)
- 문장에서 '없다','이다','같다'를 찾으면 됨
대립가설 (alternative hypothesis, H₁)
- 우리가 주장하는 가설 (연구가설)
양측검정
- 귀무가설 : 라떼의 중량은 정량이다. / 인종 차별이 없다.
- 대립가설 : 라떼의 중량은 정량미달이다. / 인종 차별이 있다.
단측검정
- 귀무가설 : 건강에 대해 관심이 높아지지 않는다.
- 대립가설 : 건강에 대해 관심이 높아졌다.
가설을 검증할때 귀무가설을 기준으로 통계적으로 의미가 있는지 판단한 후 대립가설의 채택 여부를 판단하게 된다.
이때 분석가가 주장하고자 하는 대립가설이 채택되려면 p-value(귀무가설이 참이라고 지지하는 확률)는 당연히 작아진다.
p-value가 작아질수록 대립가설이 통계적으로 의미를 갖는다.
일반적으로 0.05이하 일때 통계적으로 의미가 있다고 인정한다.
p-value >= 0.05 : 기존사실(귀무가설)을 그대로 사용(대립가설 기각)
p-value < 0.05 : 대립가설 채택
'인공지능 > 머신러닝' 카테고리의 다른 글
| Confusion Matrix 혼동 행렬 쉽게 이해하기 (2) | 2021.08.23 |
|---|---|
| 회귀분석 코딩하기 (R, 파이썬) (0) | 2020.06.11 |
| 평균, 분산, 상관분석 (0) | 2020.06.09 |
| 군집화 (0) | 2020.06.08 |
| 연관규칙 / 연관성 분석 (0) | 2020.05.28 |