
logistic regression
- 분류를 하는데 있어서 가장 흔한 경우는 이분법을 기준을 분류하는 경우
- 예) 특정고객이 물건을 구매할지(1) 안할것인지(0)
어떤 기업이 부도가 날것인지(1) 안날것인지(0)
동훈이랑 서영이랑 친구인지(1) 아닌지(0)
오늘 비가 올것인지(1) 안올것인지(0)
- 적용분야 :
기업의 부도예측, 주가, 환율, 금리등의 Up/Down 예측
R로 코딩하기
1. 성적 예측
|
# 데이터 불러오기 |
 |
|
# 공분산 구하기 |
 |
|
# 컬럼이름만 써도 되게 만들기(score$) attach(score) l <- lm(성적 ~ IQ) |
 |
| # 분석 결과 확인 summary(l) |
 |
|
# IQ가 130일때 시험 성적 예측 130*0.6714 |
 |
|
# 그래프로 그리기 plot(IQ,성적,col="blue") abline(l,col='red') |
 |
|
# 다중회귀식 만들기 lm(성적 ~ IQ+다니는학원수+게임하는시간+TV시청시간) |
 |
2. 보험비용 예측
| # 데이터 불러오기 insurance <- read.csv("C:/data/insurance.csv") |
 |
|
# 종속변수와 독립변수간의 상관계수 확인 cor(insurance[,c("age","bmi","children","charges")]) |
 |
|
# 정규화작업을 하지않고 회귀식만들기 l <- lm(charges ~ age+bmi+children, data=insurance) |
 |
| # 분석결과 확인 summary(l) |
 |
|
# 정규화작업을 하고 회귀식만들기 normalize <- function(x){ return ((x-min(x))/(max(x)-min(x))) } insurance[1] <- lapply(insurance[1],normalize) insurance[3] <- lapply(insurance[3],normalize) insurance[4] <- lapply(insurance[4],normalize) l <- lm(charges ~ age+bmi+children, data=insurance) summary(l) |
 |
|
# 모든 컬럼 사용 lm(charges ~ ., data=insurance) |
 |
|
# 지정 컬럼 빼고 사용 lm(charges ~ .-region, data=insurance) |
 |
|
insurance <- read.csv("C:/data/insurance.csv") insurance$bmi30 <- ifelse(insurance$bmi >= 30,1,0) head(insurance) |
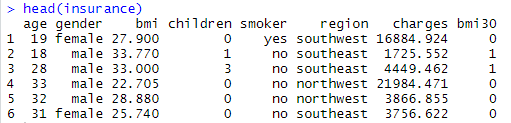 |
| l <- lm(charges ~ age + children + bmi + bmi30*smoker, data=insurance) summary(l) |
 |
|
l <- lm(charges ~ age + bmi30 + smoker + bmi30*smoker, data=insurance) |
 |
파이썬으로 코딩하기
1. 몸무게 예측하기
|
# 데이터셋 만들기 |
|
|
# 회귀분석 from scipy import stats stats.linregress(height, weight) |
 |
| # 분석결과 확인 slope,intercept,rvalue,pvalue,stderr = stats.linregress(height, weight) |
 |
|
# 그래프로 그리기 import matplotlib.pyplot as plt import numpy as np
plt.scatter(height, weight) plt.plot(np.array(height), slope*np.array(height)+intercept,c='red') |
 |
2. 성적 예측
|
# 데이터 불러오기 |
 |
| # 회귀분석 stats.linregress(score['성적'],score['IQ']) |
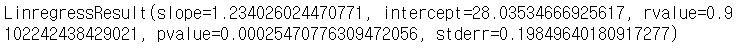 |
| # 분석결과 확인 slope,intercept,rvalue,pvalue,stderr = stats.linregress(score['IQ'],score['성적']) |
 |
|
from sklearn import linear_model # 인스턴스 만들기 reg = linear_model.LinearRegression() reg.fit(score.iloc[:,2:],score['성적']) print("기울기 :", reg.coef_) print("절편 :", reg.intercept_) |
 |
3. 보험비용 예측
|
# 데이터 불러오기 insurance = pd.read_csv("C:/pypy/insurance.csv") insurance.info() |
 |
|
# 이진분류 직접짜보기 insurance['gender_female'] = [1 if i == 'female' else 0 for i in insurance['gender']] insurance['gender_male'] = [1 if i == 'male' else 0 for i in insurance['gender']] insurance |
 |
|
# get_dummies로 원핫인코딩 dummy_gender = pd.get_dummies(insurance['gender'],prefix='gender_') |
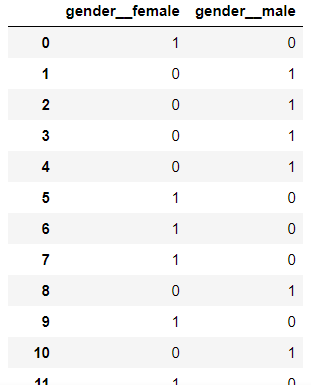 |
| # 흡연자 dummy_smoker = pd.get_dummies(insurance['smoker'],prefix='smoker_') dummy_smoker |
 |
| # 더미 데이터 합치기 data = dummy_gender.join(dummy_smoker) data |
 |
| # 컬럼 확인 insurance[['age','bmi','children','charges']] |
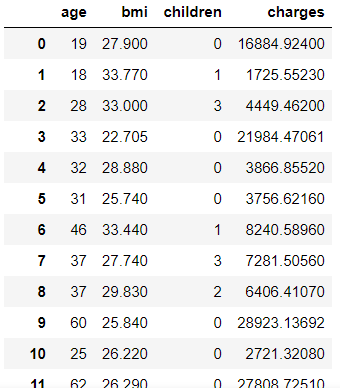 |
|
# 컬럼 합치기 |
 |
|
# 회귀분석 |
 |
4. 붓꽃 데이터
|
# 라이브러리 & 데이터 불러오기 |
 |
|
# 종속변수, 독립변수 나누기 y = iris["Name"] y |
  |
|
# 학습 데이터를 객체 내에 저장 logre = LogisticRegression() logre.fit(x,y) |
 |
|
# 새로운 데이터 넣어보기 new = [[5.1,3.5,1.4,0.2]] |
|
| # 새로운 데이터 예측 logre.predict(new) |
 |
|
# iris data set의 마지막 행 데이터 넣어보기 logre.predict(np.array(iris.iloc[149,:-1]).reshape(1,-1)) #-- 형 변환이 필요함 #-- 열의 개수는 알지 못함으로 -1기재 (1,-1) / 행의 개수를 알지 못한다면 (-1,1) |
 |
5. statsmodels로 회귀분석
| # 라이브러리 불러오기 import statsmodels.api as sm |
|
|
# 데이터 불러오기 및 구조 확인 |
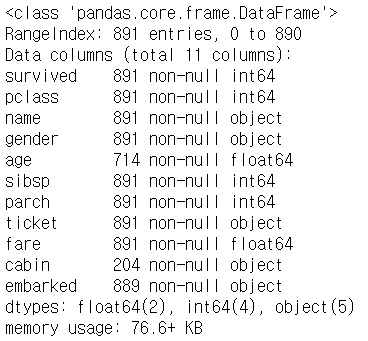 |
|
# na값 확인 df.isnull().sum() |
 |
|
# pd.get_dummies() : 자동으로 원핫인코딩 dummy_gender = pd.get_dummies(df['gender'],prefix='gender') dummy_pclass = pd.get_dummies(df['pclass'],prefix='pclass') |
|
|
# 필요한 컬럼 + 원핫 인코딩 컬럼 cols = ['survived','age','fare'] df[cols] data = df[cols].join(dummy_gender) data = data.join(dummy_pclass) data |
 |
|
# 중앙값으로 na값 채우기 data['age'].fillna(data['age'].median(), inplace=True) data['age'].isnull().sum() # na값 확인 |
|
|
# 회귀분석 결과 확인 |
  |
|
# 나이하고 요금만 했을때 cols = ['survived','age','fare'] x = data[cols] logit_x = sm.Logit(x['survived'],x.iloc[:,1:]) result_x = logit_x.fit() result_x.summary() |
 |
|
# 나이, 요금, 여성만 했을때 cols = ['survived','age','fare','gender_female'] y = data[cols] logit_y = sm.Logit(y['survived'],y.iloc[:,1:]) result_y = logit_y.fit() result_y.summary() |
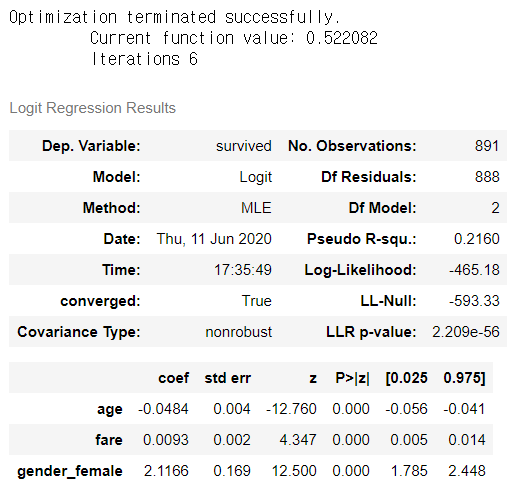 |
|
# 나이, 요금, 여성, 1등급만 해보기 cols = ['survived','age','fare','gender_female','pclass_1'] z = data[cols] logit_z = sm.Logit(z['survived'],z.iloc[:,1:]) result_z = logit_z.fit() result_z.summary() |
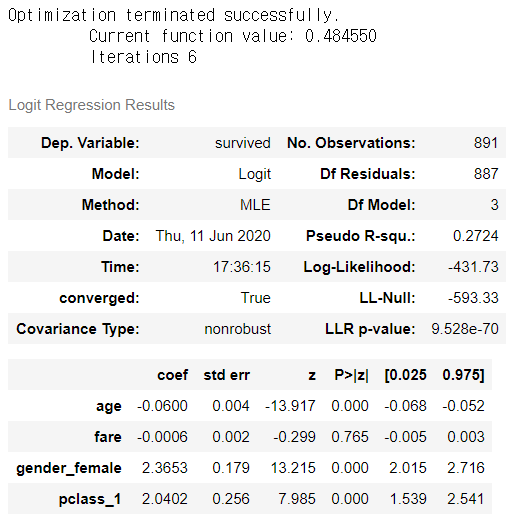 |
'인공지능 > 머신러닝' 카테고리의 다른 글
| Confusion Matrix 혼동 행렬 쉽게 이해하기 (2) | 2021.08.23 |
|---|---|
| 회귀분석 (0) | 2020.06.11 |
| 평균, 분산, 상관분석 (0) | 2020.06.09 |
| 군집화 (0) | 2020.06.08 |
| 연관규칙 / 연관성 분석 (0) | 2020.05.28 |