
stringr 라이브러리 임포트
library(stringr)
1. str_detect
: 특정한 문자가 있는지 검사해서 TRUE/FALSE를 출력하는 함수
|
text <- c("sql","SQL","Sql100", "PYTHON", "Python", "python", 일때
|
|
|
# SQL 찾기 : bool형식으로 나옴 |
 |
|
# 소문자 s로 시작되는 찾기 # 대문자 S로 시작되는 찾기 text[str_detect(text,'^S')] # 소문자,대문자 s로 시작되는 찾기 text[str_detect(text,'^[sS]')]
text[str_detect(text,'[^sS]')]
text[str_detect(text,'[sS]')]
text[str_detect(text,'$n')] |
 |
2. str_count
: 주어진 단어에서 해당글자가 몇번 나오는지 알려주는 함수
|
x <- c("Sqls","ssqls","SQL") 일때 |
|
|
# 소문자 s가 몇개가 나오는지 # 대문자 s가 몇개가 나오는지 str_count(x,"S") |
 |
3. str_c
: 문자열을 합쳐서 출력하는 함수
|
# 그냥 이어서 합치기 str_c("R","빅데이터 분석") |
 |
|
x <- "R" |
 |
|
# 사이에 문자를 넣고 문장으로 합치기 x <- c("R","빅데이터 분석") str_c(x,collapse=",")
|
 |
4. str_dup
: 주어진 문자열을 주어진 횟수만큼 반복해서 출력하는 함수
|
str_dup("취업하고 싶다",10) |
 |
5. str_length
: 문자열의 길이를 출력하는 함수
|
str_length("제주도 가고 싶다.") |
 |
6. str_locate
: 문자열에서 특정 문자가 처음으로 나오는 위치
|
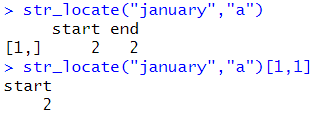
# 매트릭스 형식으로 나옴 str_locate("january","a") str_locate("january","a")[1,1] |
 |
7. str_locate_all
: 문자열에서 특정 문자가 나오는 모든 위치
|
# 리스트 형식으로 나옴 str_locate_all("january","a") |
 |
|
str_locate_all("january","a")[[1]][1,][1] str_locate_all("january","a")[[1]][2,1] str_locate_all("january","a")[[1]][2,2] |
  |
8. str_replace
: 주어진 문자열에서 처음으로 나온 문자를 변경하는 함수
| str_replace("빅데이터분석","빅데이터","가치") str_replace("banana","a","*") |
 |
|
# 다 바꾸려면 str_replace_all 사용 str_replace_all("banana","a","*") |
 |
9. str_split
: 문자열에서 지정한 기호를 기준으로 분리하는 함수
|
x <- str_c('sql','/','python','/','R') 일때 |
|
|
# 리스트 형태로 나옴 str_split(x,'/') |
 |
|
# 리스트 -> 벡터모양으로 바꾸기 unlist(str_split(x,'/')) |
 |
10. str_sub
: 문자열에서 지정된 시작 인덱스부터 끝 인덱스까지 문자를 추출하는 함수
| str_sub("행복하게 살자",start=6, end=7) str_sub("행복하게 살자",start=-4, end=7) str_sub("행복하게 살자",start=-4, end=-2) |
 |
11. str_trim
: 문자열에서 접두, 접미 부분에 공백 문자를 제거하는 함수
|
str_trim(" R ") |
 |
12. str_extract()
: 문자열을 찾는 함수
|
text <- c("sql","SQL","Sql100", "PYTHON", "Python", "python", 일때 |
|
|
# str_extract : 첫 단어만 grep("[[:digit:]]",text,value=T) |
 |
|
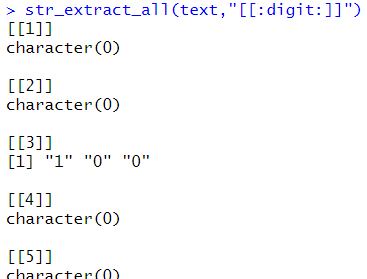
# str_extract_all : 문자 전체 str_extract_all(text,"[[:digit:]]") |
  |
|
# simplify : 행렬로 변환 str_extract_all(text,"[[:digit:]]{1,}", simplify=T) |
 |
'컴퓨터 > R' 카테고리의 다른 글
| R - 크롤링 (0) | 2020.04.27 |
|---|---|
| R - KoNLP 설치 및 사용 (0) | 2020.04.25 |
| R - wordcloud (0) | 2020.04.23 |
| R - 시각화 ⑤ ggplot 라이브러리 사용(히스토그램, 상자그림) (0) | 2020.04.23 |
| R - 시각화 ④ ggplot 라이브러리 사용(막대그래프) (0) | 2020.04.22 |