
1. 데이터 준비
1) DataLoader 작성
|
# 구글 드라이브와 구글 코랩을 연동 from google.colab import drive drive.mount('/content/gdrive') |
|
# 라이브러리 불러오기 import torch from torch import nn, optim from torch.utils.data import (Dataset, DataLoader, TensorDataset) import tqdm |
|
# DataLoader 작성 from torchvision.datasets import ImageFolder from torchvision import transforms |
|
# ImageFolder 함수를 사용해서 Dataset 작성 train_imgs = ImageFolder("/content/gdrive/My Drive/taco_and_burrito/train/", transform=transforms.Compose([transforms.RandomCrop(224), transforms.ToTensor()])) test_imgs = ImageFolder("/content/gdrive/My Drive/taco_and_burrito/test/", transform=transforms.Compose([transforms.RandomCrop(224), transforms.ToTensor()])) |
|
# DataLoader 작성 train_loader = DataLoader( train_imgs, batch_size=32, shuffle=True) test_loader = DataLoader( test_imgs, batch_size=32, shuffle=False) |
2) 분류명과 분류 인덱스 대응 관계 확인
|
# 클래스 확인 print(train_imgs.classes) |
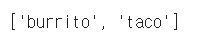 |
|
# 클래스의 인덱스 확인 print(train_imgs.class_to_idx) |
 |
2. 파이토치를 사용한 전이 학습
1) 사전 학습이 끝난(Pre-trained) 모델 불러오기 및 정의
|
# 라이브러리 불러오기 from torchvision import models |
|
# 사전 학습이 완료된 resnet18 불러오기 net = models.resnet18(pretrained=True) |
|
# 모든 파라미터를 미분 대상에서 제외한다. for p in net.parameters(): p.requires_grad = False |
|
# 마지막 선형 계층을 변경한다. fc_input_dim = net.fc.in_features net.fc = nn.Linear(fc_input_dim, 2) |
2) 모델의 훈련 함수 작성
|
# eval_net 만들기 def eval_net(net, data_loader, device="cpu"): # Dropout 및 BatchNorm을 무효화 net.eval() ys = [] ypreds = [] for x, y in data_loader: # to 메서드로 계산을 실행할 디바이스 전송 x = x.to(device) y = y.to(device) # 확률이 가장 큰 분류를 예측 # 여기선 forward(추론) 계산이 전부이므로 자동 미분에 필요한 처리는 off로 설정해서 불필요한 계산을 제한다. with torch.no_grad(): _, y_pred = net(x).max(1) ys.append(y) ypreds.append(y_pred)
# 미니 배치 단위의 예측 결과 등을 하나로 묶는다 ys = torch.cat(ys) ypreds = torch.cat(ypreds) # 예측 정확도 계산 acc = (ys == ypreds).float().sum() / len(ys) return acc.item() |
|
# train_net 만들기 def train_net(net, train_loader, test_loader, only_fc=True, optimizer_cls=optim.Adam, loss_fn=nn.CrossEntropyLoss(), n_iter=10, device="cpu"): train_losses = [] train_acc = [] val_acc = [] if only_fc: # 마지막 선형 계층의 파라미터만 optimizer에 전달 optimizer = optimizer_cls(net.fc.parameters()) else: optimizer = optimizer_cls(net.parameters()) for epoch in range(n_iter): running_loss = 0.0 # 신경망을 훈련 모드로 설정 net.train() n = 0 n_acc = 0 # 시간이 많이 걸리므로 tqdm을 사용해서 진행 바를 표시 for i, (xx, yy) in tqdm.tqdm(enumerate(train_loader), total=len(train_loader)): xx = xx.to(device) yy = yy.to(device) h = net(xx) loss = loss_fn(h, yy) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() n += len(xx) _, y_pred = h.max(1) n_acc += (yy == y_pred).float().sum().item() train_losses.append(running_loss/i) # 훈련 데이터의 예측 정확도 train_acc.append(n_acc / n)
# 검증 데이터의 예측 정확도 val_acc.append(eval_net(net, test_loader, device)) # epoch의 결과 표시 print(epoch, train_losses[-1], train_acc[-1], val_acc[-1], flush=True) |
3) 모든 파라미터를 GPU로 전송해서 훈련 실행
|
# 신경망의 모든 파라미터를 GPU로 전송 net.to("cuda:0") |
 |
|
# 훈련 실행 train_net(net, train_loader, test_loader, n_iter=20, device="cuda:0") |
  |
4) 입력을 그대로 출력하면 더미 계층을 만들어 fc를 변경
|
# 마지막층 만들기 class FlattenLayer(nn.Module): def forward(self, x): sizes = x.size() return x.view(sizes[0], -1)
class IdentityLayer(nn.Module): def forward(self, x): return x
net = models.resnet18(pretrained=True) for p in net.parameters(): p.requires_grad=False net.fc = IdentityLayer() |
5) 새로운 CNN 모델 실행
|
# CNN 모델 conv_net = nn.Sequential( nn.Conv2d(3, 32, 5), nn.MaxPool2d(2), nn.ReLU(), nn.BatchNorm2d(32), nn.Conv2d(32, 64, 5), nn.MaxPool2d(2), nn.ReLU(), nn.BatchNorm2d(64), nn.Conv2d(64, 128, 5), nn.MaxPool2d(2), nn.ReLU(), nn.BatchNorm2d(128), FlattenLayer() ) |
|
|
# 합성곱에 의해 최종적으로 어떤 크기인지 실제로 데이터를 넣어서 확인 test_input = torch.ones(1, 3, 224, 224) conv_output_size = conv_net(test_input).size()[-1] |
|
|
# 최종 CNN net = nn.Sequential( conv_net, nn.Linear(conv_output_size, 2) ) |
|
|
# 신경망의 모든 파라민터를 GPU로 전송 net.to("cuda:0") |
 |
|
# 훈련 실행 train_net(net, train_loader, test_loader, n_iter=10, only_fc=False, device="cuda:0") |
 |
'인공지능 > 파이토치' 카테고리의 다른 글
| 파이토치 - CNN을 사용한 이미지 분류 (Fashion-MNIST) (0) | 2020.07.21 |
|---|---|
| 파이토치 - 신경망의 모듈화 (0) | 2020.07.20 |
| 파이토치 - Dropout과 Batch Normalization (0) | 2020.07.20 |
| 파이토치 - Dataset과 DataLoader (0) | 2020.07.20 |
| 파이토치 - MLP 구축과 학습 (0) | 2020.07.20 |