
1. Dropout을 사용한 정규화
1) 신경망 구성
|
# 라이브러리 불러오기 import torch from torch import nn, optim from torch.utils.data import TensorDataset, DataLoader from sklearn.datasets import load_digits digits = load_digits() |
|
# 데이터를 훈련용과 검증용으로 분할 from sklearn.model_selection import train_test_split # 전체의 30%는 검증용 X = digits.data Y = digits.target X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3)
|
|
# 텐서로 변환 X_train = torch.tensor(X_train, dtype=torch.float32) Y_train = torch.tensor(Y_train, dtype=torch.int64) X_test = torch.tensor(X_test, dtype=torch.float32) Y_test = torch.tensor(Y_test, dtype=torch.int64) |
|
# 여러 층을 쌓아서 깊은 신경망을 구축한다. k = 100 net = nn.Sequential( nn.Linear(64, k), nn.ReLU(), nn.Linear(k, k), nn.ReLU(), nn.Linear(k, k), nn.ReLU(), nn.Linear(k, k), nn.ReLU(), nn.Linear(k, 10) ) |
|
# CrossEntropy, Adam Optimizer 사용 loss_fn = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters()) |
|
# 훈련용 데이터로 DataLoader를 작성 ds = TensorDataset(X_train, Y_train) loader = DataLoader(ds, batch_size=32, shuffle=True) |
|
# 100에폭 실행 train_losses = [] test_losses = [] for epoch in range(100): running_loss = 0.0 for i, (xx, yy) in enumerate(loader): y_pred = net(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() train_losses.append(running_loss / i) y_pred = net(X_test) test_loss = loss_fn(y_pred, Y_test) test_losses.append(test_loss.item()) |
|
# 정답률 _, y_pred = torch.max(net(X_test), 1) (y_pred == Y_test).sum().item() / len(Y_test) |
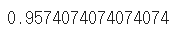 |
2) train과 eval 메서드로 Dropout 처리 적용/미적용
|
# dropout을 포함한 네트워크 구성 net = nn.Sequential( nn.Linear(64, k), nn.ReLU(), nn.Dropout(0.5), nn.Linear(k, k), nn.ReLU(), nn.Dropout(0.5), nn.Linear(k, k), nn.ReLU(), nn.Dropout(0.5), nn.Linear(k, k), nn.ReLU(), nn.Dropout(0.5), nn.Linear(k, 10) ) |
|
# Adam oprimizer 적용 optimizer = optim.Adam(net.parameters()) |
|
# 100에폭 실행 train_losses = [] test_losses = [] for epoch in range(100): running_loss = 0.0 for i, (xx, yy) in enumerate(loader): y_pred = net(xx) loss = loss_fn(y_pred, yy) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() train_losses.append(running_loss / i) # 신경망을 평가모드로 설정하고 검증 데이터의 손실함수를 계산 net.eval() y_pred = net(X_test) test_loss = loss_fn(y_pred, Y_test) test_losses.append(test_loss.item()) |
|
# 정답률 _, y_pred = torch.max(net(X_test), 1) (y_pred == Y_test).sum().item() / len(Y_test) |
 |
2. Batch Normalization를 사용한 학습 가속
1) train과 eval 메서드로 Batch Normalization 모드를 적용/미적용할 수 있다.
|
# Linear층에는 BatchNorm1d를 적용한다. net = nn.Sequential( nn.Linear(64, k), nn.ReLU(), nn.BatchNorm1d(k), nn.Linear(k, k), nn.ReLU(), nn.BatchNorm1d(k), nn.Linear(k, k), nn.ReLU(), nn.BatchNorm1d(k), nn.Linear(k, k), nn.ReLU(), nn.BatchNorm1d(k), nn.Linear(k, 10) ) |
'인공지능 > 파이토치' 카테고리의 다른 글
| 파이토치 - CNN을 사용한 이미지 분류 (Fashion-MNIST) (0) | 2020.07.21 |
|---|---|
| 파이토치 - 신경망의 모듈화 (0) | 2020.07.20 |
| 파이토치 - Dataset과 DataLoader (0) | 2020.07.20 |
| 파이토치 - MLP 구축과 학습 (0) | 2020.07.20 |
| 파이토치 - 로지스틱 회귀 (0) | 2020.07.20 |