
목표
- 시카고 샌드위치 맛집 리스트 정리
사용 데이터
1. 시카고 샌드위치 맛집 사이트 : https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/
The 50 Best Sandwiches in Chicago
Our list of Chicago’s 50 best sandwiches, ranked in order of deliciousness
www.chicagomag.com
1. 시카고 샌드위치 맛집 소개 사이트에 접근하기
# 라이브러리 불러오기
|
from bs4 import BeautifulSoup |
# html 코드 다 받기
|
url_base = 'https://www.chicagomag.com/' html = urlopen(url) soup = BeautifulSoup(html, "html.parser")
soup |
 |
# 찾으려는 내용(샌드위치 맛집) 확인
| print(soup.find_all('div', 'sammy')) |
 |
# 맛집 개수로 확인
| len(soup.find_all('div', 'sammy')) |
 |
# 첫번째 정보 확인
| print(soup.find_all('div', 'sammy')[0]) |
 |
2. 접근한 웹페이지에서 원하는 데이터 추출하고 정리하기
# 랭킹 정보 얻기 (1위)
|
tmp_one = soup.find_all('div', 'sammy')[0] |
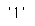 |
# 메뉴 이름과 가게 이름 (1위)
| tmp_one.find(class_='sammyListing').get_text() |
 |
# 클릭했을 때 연결된 주소 저장
| tmp_one.find('a')['href'] |
 |
# 정규식을 사용하여 메뉴이름과 가게이름 분리
|
import re tmp_string = tmp_one.find(class_='sammyListing').get_text() re.split(('\n|\r\n'),tmp_string)
print(re.split(('\n|\r\n'),tmp_string)[0]) print(re.split(('\n|\r\n'),tmp_string)[1]) |
 |
# 순위, 메인 메뉴, 카페 이름, url 주소 저장
|
rank = [] list_soup = soup.find_all('div', 'sammy')
for item in list_soup : rank.append(item.find(class_='sammyRank').get_text()) tmp_string = item.find(class_='sammyListing').get_text() main_menu.append(re.split(('\n|\r\n'), tmp_string)[0]) cafe_name.append(re.split(('\n|\r\n'), tmp_string)[1]) url_add.append(urljoin(url_base, item.find('a')['href'])) |
# 순위, 메인 메뉴, 카페 이름, URL 주소 확인
| rank[:5] |
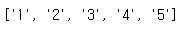 |
| main_menu[:5] |
 |
| cafe_name[:5] |
 |
| url_add[:5] |
 |
# 저장 개수 확인
| len(rank), len(main_menu), len(cafe_name), len(url_add) |
 |
# 데이터 프레임 만들기 (데이터 정리)
|
import pandas as pd data = {'Rank':rank, 'Menu':main_menu, 'Cafe':cafe_name, 'URL':url_add} df = pd.DataFrame(data) df.head() |
 |
# 컬럼 순서 정리
|
df = pd.DataFrame(data, columns=['Rank','Cafe','Menu','URL']) |
 |
# 데이터 프레임 csv로 저장
| df.to_csv("C:/datascience_train/data/03. best_sandwiches_list_chicago.csv", sep=',', encoding='UTF-8') |
3. 다수의 웹 페이지에 자동으로 접근해서 원하는 정보 가져오기
# 첫번째 URL 확인
| df['URL'][0] |
 |
# 첫번째 URL의 html읽기
|
html = urlopen(df['URL'][0]) |
 |
# 주소, 가격, 전화번호 부분 찾아서 출력
| print(soup_tmp.find('p', 'addy')) |
 |
# 텍스트로 가져오기
|
price_tmp = soup_tmp.find('p', 'addy').get_text() |
 |
# 나누기
| price_tmp.split() |
 |
# 가격 확인
| price_tmp.split()[0] |
 |
# 가격 뒤에 '.'빼기
| price_tmp.split()[0][:-1] |
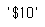 |
# 주소 확인
| ' '.join(price_tmp.split()[1:-2]) |
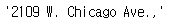 |
# 3페이지에서 가격과 주소 가져오기
|
price = [] for n in df.index[:3]: html = urlopen(df['URL'][n]) soup_tml = BeautifulSoup(html, 'lxml') gettings = soup_tmp.find('p', 'addy').get_text()
price.append(gettings.split()[0][:-1]) address.append(' '.join(gettings.split()[1:-2])) |
# 3페이지의 가격과 주소 확인
| price, address |
 |
4. 50개 웹페이지에 대한 정보 가져오기
# tqdm을 적용하여 50페이지 핸들링
|
from tqdm import tqdm price = [] address = []
for n in tqdm(df.index): html = urlopen(df['URL'][n]) soup_tml = BeautifulSoup(html, 'lxml') gettings = soup_tmp.find('p', 'addy').get_text()
price.append(gettings.split()[0][:-1]) address.append(' '.join(gettings.split()[1:-2])) |
 |
# 저장된 개수 확인
| len(price), len(address), len(df) |
 |
# df에 가격과 주소 추가
|
df['price'] = price df = df.loc[:, ['Rank', 'Cafe', 'Menu', 'Price', 'Address']] df.set_index('Rank', inplace=True) df.head() |
 |
# 결과 저장
| df.to_csv("C:/datascience_train/data/03. best_sandwiches_list_chicago2.csv", sep=',', encoding='UTF-8') |
5. 맛집 위치를 지도에 표기하기
# 필요한 라이브러리 불러오기
| import folium import pandas as pd import googlemaps import numpy as np |
# 데이터 불러오기
|
df = pd.read_csv("C:/datascience_train/data/03. best_sandwiches_list_chicago2.csv", index_col=0) |
 |
# googlemaps 읽어오기
|
gmaps_key = '**************************' |
# 50개 맛집의 위도, 경도 정보 받아오기
|
lat = []
for n in tqdm(df.index): if df['Address'][n] != 'Multiple': target_name = df['Address'][n]+', '+'Cicago' gmaps_output = gmaps.geocode(target_name) location_output = gmaps_output[0].get('geometry') lat.append(location_output['location']['lat']) lng.append(location_output['location']['lng'])
else : lat.append(np.nan) lng.append(np.nan) |
 |
# 위도,경도 컬럼 추가
|
df['lat'] = lat |
 |
# 50개 맛집의 위도, 경도의 평균값을 중앙에 두기
|
mapping = folium.Map(location=[df['lat'].mean(), df['lng'].mean()], zoom_start=11) |
 |
# 50개 맛집의 위도, 경도를 지도에 표기
|
mapping = folium.Map(location=[df['lat'].mean(), df['lng'].mean()], zoom_start=11) for n in df.index: if df['Address'][n] != 'Multiple': folium.Marker([df['lat'][n], df['lng'][n]], popup=df['Cafe'][n]).add_to(mapping)
mapping |
 |
'인공지능 > 데이터 사이언스' 카테고리의 다른 글
| 데이터 분석 연습2 - 서울시 범죄 현황 분석 (1) | 2020.06.19 |
|---|---|
| 데이터 분석 연습1 - 서울시 구별 CCTV 현황 분석 (0) | 2020.05.10 |
| 소셜 데이터 마이닝 분석 (0) | 2020.02.22 |
| 소셜 빅데이터 마이닝 개념과 분석 유형 (0) | 2020.02.20 |
| 관계형 데이터 모델의 기초 (0) | 2020.01.19 |