
목표
- 어디에 CCTV가 많이 설치됐는지?
- 구별 인구 대비 비율
- 구별 인구 현황
- 구별 CCTV 현황 (시각화)
사용 데이터
1. 서울시 자치구 연도별 cctv 설치 현황 (.csv)
2. 서울시 인구 통계 (.xls)
1. pandas로 텍스트 파일과 엑셀 파일 읽기
# pandas 불러오기
| import pandas as pd |
# CSV파일 읽어들이기
|
CCTV_Seoul = pd.read_csv("C:/datascience_train/data/01. CCTV_in_Seoul.csv", encoding='utf-8') |
 |
# 컬럼 이름 변경하기 (기관명 -> 구별)
# inplace=True : 실제 CCTV_Seoul의 내용을 변경
|
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]:'구별'}, inplace=True) |
 |
# 엑셀 파일 읽어들이기
|
pop_Seoul = pd.read_excel("C:/datascience_train/data/01. population_in_Seoul.xls", encoding='utf-8') |
 |
# 엑셀 파일 읽어들이기
# header = 2 : 세 번째 줄부터 읽기
# parse_cols = 'B, D ,G, J, N' : B, D ,G, J, N 열만 읽도록 하기
|
pop_Seoul = pd.read_excel("C:/datascience_train/data/01. population_in_Seoul.xls", encoding='utf-8', |
 |
# 컬럼 이름 변경하기
|
pop_Seoul.rename(columns = {pop_Seoul.columns[0]:'구별', |
 |
2. CCTV와 인구 현황 데이터 파악하기
CCTV 데이터 파악하기
| CCTV_Seoul.head() |
 |
# CCTV 전체 개수 (소계)로 오름차순 정렬
| CCTV_Seoul.sort_values(by='소계', ascending=True).head(5) |
 |
# CCTV 전체 개수 (소계)로 내림차순 정렬
| CCTV_Seoul.sort_values(by='소계', ascending=False).head(5) |
 |
# 최근 3년간 CCTV 증가율 계산
| CCTV_Seoul['최근증가율'] = (CCTV_Seoul['2016년']+CCTV_Seoul['2015년']+CCTV_Seoul['2014년']) / CCTV_Seoul['2013년도 이전'] * 100 CCTV_Seoul.sort_values(by='최근증가율', ascending=False).head(5) |
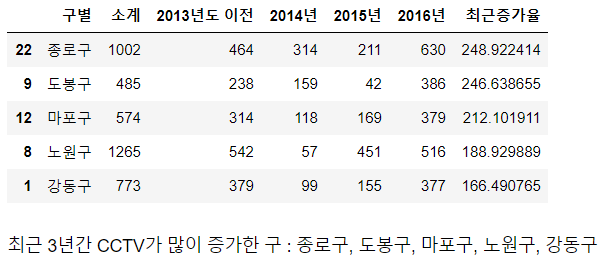 |
인구 현황 데이터 파악하기
| pop_Seoul.head() |
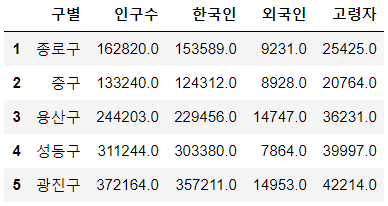 |
# '합계'행 지우기
|
pop_Seoul.drop([0], inplace=True) |
 |
# '구별' 컬럼의 유일값 찾아내기
| pop_Seoul['구별'].unique() |
 |
# NaN값 추출하기
| pop_Seoul[pop_Seoul['구별'].isnull()] |
 |
# NaN값 행 삭제
|
pop_Seoul.drop([26], inplace=True) |
 |
# 구별 외국인 비율과 고령자 비율 계산
|
pop_Seoul['외국인비율'] = pop_Seoul['외국인']/pop_Seoul['인구수']*100 |
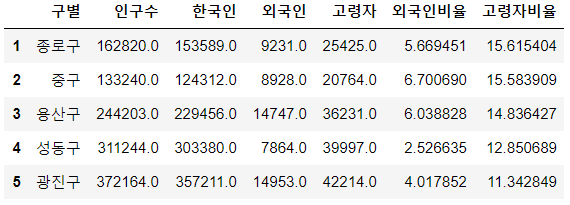 |
# 인구수가 많은 순으로 정렬
| pop_Seoul.sort_values(by='인구수', ascending=False).head(5) |
 |
# 인구수가 많은 순으로 정렬
| pop_Seoul.sort_values(by='인구수', ascending=False).head(5) |
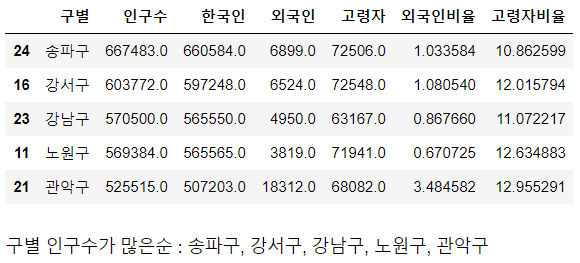 |
# 외국인 수가 많은 순으로 정렬
| pop_Seoul.sort_values(by='외국인', ascending=False).head(5) |
 |
# 외국인 비율이 높은 순으로 정렬
| pop_Seoul.sort_values(by='외국인비율', ascending=False).head(5) |
 |
# 고령자 수가 많은 순으로 정렬
| pop_Seoul.sort_values(by='고령자', ascending=False).head(5) |
 |
# 고령자 비율이 높은 순으로 정렬
| pop_Seoul.sort_values(by='고령자비율', ascending=False).head(5) |
 |
3. CCTV 데이터와 인구 현황 데이터 합치고 분석하기
# 공통된 컬럼('구별')으로 CCTV데이터와 인구 현황 데이터 합치기
|
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on='구별') |
 |
# 의미없는 컬럼 지우기
# 행 방향 삭제 : drop / 열 방향 삭제 : del
|
del data_result['2013년도 이전'] |
 |
# '구별' 컬럼 값을 인덱스로 사용하기
|
data_result.set_index('구별', inplace=True) |
 |
상관관계 분석하기
- 고령자비율, 외국인비율, 인구수 중에서 무슨 데이터와 CCTV를 비교할지 정하기
- 상관계수의 절대값이 클수록 두 데이터는 관계가 있다고 볼 수 있다.
- 절대값 0.1 이하 : 거의 무시
- 절대값 0.3 이하 : 약한 상관관계
- 절대값 0.7 이하 : 뚜렷한 상관관계
| # 고령자 비율과 CCTV 의 상관관계 구하기 np.corrcoef(data_result['고령자비율'],data_result['소계']) |
 |
| # 외국인 비율과 CCTV 개수의 상관관계 구하기 np.corrcoef(data_result['외국인비율'],data_result['소계']) |
 |
| # 인구수와 CCTV 개수의 상관관계 구하기 np.corrcoef(data_result['인구수'],data_result['소계']) |
 |
 |
|
4. CCTV 현황 그래프로 분석하기
# matplotlib의 pyplot 불러오기
# %matplotlib inline : 그래프의 결과를 출력 세션에 나타나게 하는 설정
|
import matplotlib.pyplot as plt |
# matplotlib이 기본으로 가진 폰트는 한글을 지원하지 않기 때문에 폰트를 변경할 필요가 있다.
# 맥OS, 윈도우 둘 다 사용 가능하게 만들기
|
import platform
from matplotlib import font_manager, rc plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin': rc('font', family='AppleGothic') elif platform.system() == 'Windows': path = "C:/Windows/Fonts/malgun.ttf" font_name = font_manager.FontProperties(fname=path).get_name() rc('font', family=font_name) else: print('Unknown system... sorry~~~~') |
# 데이터 다시 확인
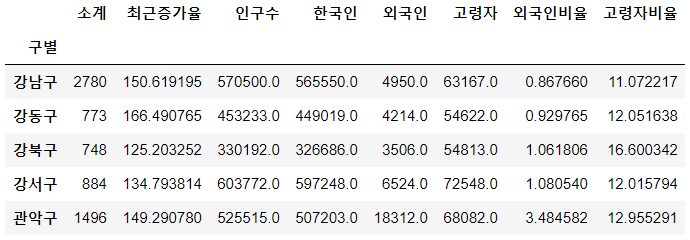
| data_result.head() |
 |
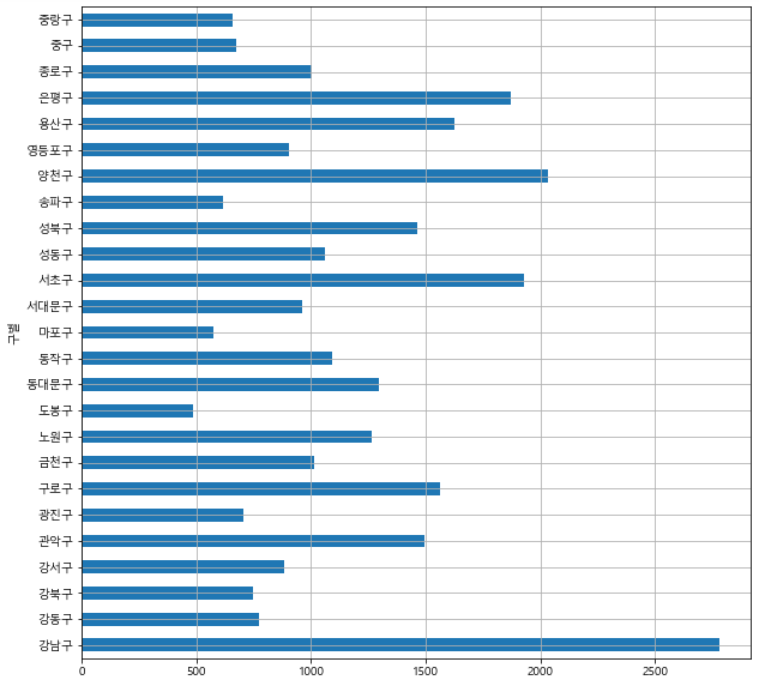
# 구별 CCTV 개수 막대그래프로 그리기
# kind='barh' : 수평바로 그리기
# grid=True : 그리드 사용
# figsize=(10,10) : 그림 크기 지정
|
data_result['소계'].plot(kind='barh', grid=True, figsize=(10,10)) |
 |
# 구별 CCTV 개수 내림차순으로 정렬 / 막대 그래프로 그리기
|
data_result['소계'].sort_values().plot(kind='barh', grid=True, figsize=(10,10)) |
  |
# 인구 대비 CCTV 비율을 계산해서 정렬 / 막대 그래프로 그리기
|
data_result['CCTV비율'] = data_result['소계'] / data_result['인구수'] * 100 |
  |
# 인구수와 CCTV의 관계를 삼전도로 그리기
|
plt.figure(figsize=(6,6)) |
 |
# 인구수와 CCTV의 관계를 대표하는 직선 그리기
| fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1) fp1 |
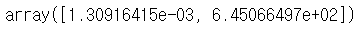 |
# x축과 y축 데이터 얻기
| fx = np.linspace(100000, 700000, 100) fy = np.poly1d(fp1) |
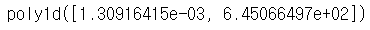 |
# 그림으로 출력하기
|
plt.figure(figsize=(10,10)) |
 |
최종 시각화
- 직선과 멀리 떨어져 있는 구의 이름 표시
- 직선에서 멀어질수록 다른 색으로 나타내기
# 오차 계산 / 오차가 큰 순으로 정렬해서 다시 저장
|
# 직선, x축, y축 구하기 fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1) fx = np.linspace(100000, 700000, 100) fy = np.poly1d(fp1)
# 오차 구하기 data_result['오차'] = np.abs(data_result['소계'] - fy(data_result['인구수'])) df_sort = data_result.sort_values(by='오차', ascending=False) df_sort.head() |
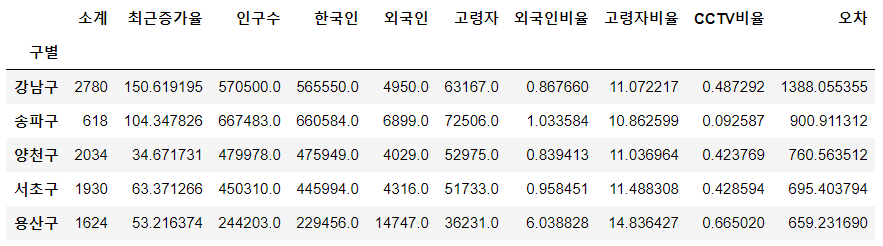 |
# 텍스트와 color map 입히기
|
plt.figure(figsize=(14,10)) for n in range(10): plt.text(df_sort['인구수'][n]*1.02, df_sort['소계'][n]*0.98, df_sort.index[n], fontsize=15)
plt.xlabel('인구수') plt.ylabel('인구당CCTV비율')
plt.colorbar().ax.set_xlabel('오차') plt.grid() plt.show() |
 |
'인공지능 > 데이터 사이언스' 카테고리의 다른 글
| 데이터 분석 연습3 - 시카고 샌드위치 맛집 분석 (0) | 2020.06.24 |
|---|---|
| 데이터 분석 연습2 - 서울시 범죄 현황 분석 (1) | 2020.06.19 |
| 소셜 데이터 마이닝 분석 (0) | 2020.02.22 |
| 소셜 빅데이터 마이닝 개념과 분석 유형 (0) | 2020.02.20 |
| 관계형 데이터 모델의 기초 (0) | 2020.01.19 |