
이미지 형태 확인
| # 라이브러리 불러오기 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from PIL import Image import glob |
|
| # 이미지 불러오기 및 확인 img = Image.open("C:/pypy/dog.jpg") plt.imshow(img) |
 |
| # 이미지 resize 모습 확인 plt.imshow(img.resize([64,64])) |
 |
| # 이미지에 대한 색상 변경 data = img.convert("RGB") |
|
| # 이미지 resize data = data.resize([64,64]) |
|
| # 이미지를 숫자 어레이 형식으로 바꾸기 data = np.asarray(data) |
|
| # 이미지 형태 바꾸기 data.reshape([1,64,64,3]) |
 |
| # 이미지 형태 확인 data.shape |
 |
CNN으로 강아지, 고양이 분류하기
| # 라이브러리 불러오기 from sklearn.model_selection import train_test_split from PIL import Image import numpy as np import tensorflow as tf import matplotlib.pyplot as plt import glob |
|
| # 이미지 데이터 경로 지정 data_dir = "C:/cats_dogs" |
|
| # 카테고리 지정 categories = ['cats','dogs'] nb_class=len(categories) |
|
| # 이미지 사이즈 지정 image_w = 64 image_h = 64 pixels = image_w * image_h * 3 |
|
| # 이미지마다 원핫 인코딩 x = [] y = [] # 폴더안에 있는 데이터 다 가져오기 # enumerate() : 리스트의 순서와 값 반환 for idx, c in enumerate(categories): label = [0 for i in range(nb_class)] label[idx] = 1 image_dir = data_dir+"/"+c files = glob.glob(image_dir+"/*.jpg") # print(files) # 파일안에 있는 이미지 오픈해서 어레이값으로 변경 for i, f in enumerate(files): img = Image.open(f) img = img.convert("RGB") img = img.resize((image_w,image_h)) data = np.asarray(img) x.append(data) y.append(label) |
  |
| # 실제 array형태로 바꾸기 / 형태 확인 x = np.array(x) x.shape y = np.array(y) y.shape |
  |
| # train / test 데이터셋 나누기 X_train, X_test, Y_train,Y_test = train_test_split(x, y, test_size=0.2) |
|
| # 어레이값 데이터셋 저장 image_data = (X_train, X_test, Y_train,Y_test) np.save("c:/data/cats_dogs_image_data.npy",image_data) |
 |
| # 저장한 어레이값 불러와서 사용 / allow_pickle=True 꼭 사용 X_train, X_test, Y_train,Y_test = np.load("c:/data/cats_dogs_image_data.npy",allow_pickle=True) X_train.shape X_test.shape Y_train.shape X_test.shape |
 |
| # 표준화 혹은 정규화 사용 #X_train = X_train.astype('float32')/255 #X_test = X_test.astype('float32')/255 |
|
| < 입력층 > | |
| # 입력변수, 출력변수 만들기 # 몇개가 들어올지 모르니까 None으로 표기 x = tf.placeholder(tf.float32,[None,64,64,3]) y = tf.placeholder(tf.float32,[None,2]) |
|
| < 은닉층 - 1층> | |
| # weight이 filter로 생각하면 된다. # 필터 크기 = [필터 가로, 필터 세로, 색수, 채널] # tf.random_normal : 정규분포에 따른 숫자를 난수값으로 표현하기(표준편차=0.01) w1 = tf.Variable(tf.random_normal([3,3,3,32],stddev=0.01)) |
|
| # stride는 네자리로 표현할뿐 [1,칸수,칸수,1] # padding='SAME' : 원본에 패딩을 0으로 채워서 크기가 변하지 않게 한다. # 패딩을 하는 이유 : 모서리부분의 중요한 이미지가 희석되는걸 방지 L1 = tf.nn.conv2d(x,w1,strides=[1,1,1,1],padding='SAME') L1 |
 |
| # ksize=[1,2,2,1] : pooling할때 쓰는 필터를 2x2 사이즈로 지정 # maxpool을 쓰더라도 이미지 크기를 같게 하려면 stride를 1, padding='SAME'로 해야한다. L1 = tf.nn.relu(L1) L1 = tf.nn.max_pool(L1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') L1 |
 |
| < 은닉층 - 2층> | |
| # 필터 : [가로, 세로, 앞단의 채널, 채널] # 필터크기 : 3x3, 스트라이드 : 1, 패딩 : same w2 = tf.Variable(tf.random_normal([3,3,32,64],stddev=0.01)) L2 = tf.nn.conv2d(L1,w2,strides=[1,1,1,1],padding='SAME') L2 |
 |
| # relu사용, max pooling 사용 L2 = tf.nn.relu(L2) L2 = tf.nn.max_pool(L2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') L2 |
 |
| < 은닉층 - 3층> | |
| # 필터크기 : 3x3, 스트라이드 : 1, 패딩 : same w3 = tf.Variable(tf.random_normal([3,3,64,64],stddev=0.01)) L3 = tf.nn.conv2d(L2,w3,strides=[1,1,1,1],padding='SAME') L3 |
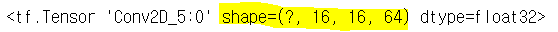 |
| # relu사용, max pooling 사용 L3 = tf.nn.relu(L3) L3 = tf.nn.max_pool(L3,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') |
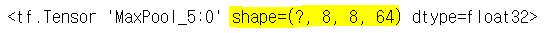 |
| < Fully connected 층> | |
| # 여기서 w4은 filter가 아닌 weight값으로 생각하면됨 # w4 = [앞단의 크기, 채널] w4 = tf.Variable(tf.random_normal([8*8*64,256],stddev=0.01)) w4 |
 |
| # [행의 수,열의 수] : -1은 모르겠다는 뜻임 L4 = tf.reshape(L3,[-1,8*8*64]) L4 |
 |
| # L4와 w4을 행렬의 곱하고 relu 적용 L4 = tf.nn.relu(tf.matmul(L4,w4)) L4 |
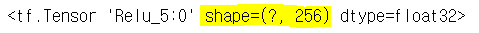 |
| < 출력층 > | |
| # [입력 개수, 출력 개수(클래스 개수)] w5 = tf.Variable(tf.random_normal([256,2],stddev=0.01)) w5 |
 |
| # L4와 w5 행렬의 곱 model = tf.matmul(L4,w5) model |
 |
| # softmax로 확률값 계산 hypothesis = tf.nn.softmax(model) |
|
| # softmax로 확률값 계산 / cross entropy로 손실값 계산 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis,labels=y)) |
|
| # AdamOptimizer는 내부적에서 모멘텀을 이용해서 학습률 조절을 좀 해결함 optimizer = tf.train.AdamOptimizer(0.001).minimize(cost) |
|
| ### 튜닝 | |
| # 세션 열고 변수 초기화 sess = tf.Session() sess.run(tf.global_variables_initializer()) |
|
| # 데이터셋이 많은 경우 미니배치를 사용하여 표본추출 batch_size = 100 for epoch in range(1,11): avg_cost = 0 # 배치사이즈만큼 뽑아서 사용 for i in range(int(np.ceil(len(X_train)/batch_size))): x_ = X_train[batch_size*i : batch_size*(i+1)] y_ = Y_train[batch_size*i : batch_size*(i+1)] _,cost_val = sess.run([optimizer,cost], feed_dict={x:x_,y:y_}) avg_cost += cost_val print('Epoch:','%04d'%(epoch), 'cost: ','{:.9f}'.format(avg_cost/len(X_train))) |
 |
| # 정확도 계산 # tf.argmax(X,n) : X 배열에서 가장 큰 값을 ‘열(1)’ 기준 몇번째인지 index를 반환 # tf.cast() : 입력한 값의 결과를 지정한 자료형으로 변환해줌 # tf.equal() : x, y를 비교하여 boolean 값을 반환 is_correct = tf.equal(tf.argmax(hypothesis,1),tf.argmax(y,1)) accuracy=tf.reduce_mean(tf.cast(is_correct,tf.float32)) print("정확도 : ",sess.run(accuracy,feed_dict={x:X_test,y:Y_test})) |
 |
| # 테스트 plt.imshow(X_test[15],cmap='Greys') data = X_test[15].reshape([1,64,64,3]) print("Prediction : ",sess.run(tf.argmax(hypothesis,1),feed_dict={x:data})) |
 |
!! 성공 코드 및 가상환경 정보 !!
반응형
'인공지능 > 딥러닝' 카테고리의 다른 글
| StarGAN v2: Diverse Image Synthesis for Multiple Domains 논문 리뷰 (1) | 2022.01.25 |
|---|---|
| CNN 코딩 기초 (0) | 2020.06.12 |
| 신경망을 이용한 붓꽃 데이터 분류하기 (0) | 2020.06.12 |
| 텐서플로를 이용한 신경망 구현 (0) | 2020.06.12 |
| 텐서플로 - 설치, 상수/변수 선언, 메소드 (0) | 2020.05.28 |