
1. apply
- 행렬, 배열, 데이터프레임에 함수를 적용한 결과를 벡터, 리스트, 배열 형태로 리턴한다.
- 행렬의 행이나 열의 방향으로 함수를 적용
- (행렬 이름, 행렬의 방향 1=행/2=열,그룹함수)
|
# 기본 사용 m <- matrix(1:4, ncol=2) apply(m,1,sum) apply(m,2,sum) |
 |
|
df <- data.frame(name = c("king","smith","jane"),  |
|
|
# 행별 열의 합 apply(df[,c(2,3)],1,sum) apply(df[,c(2,3)],1,sum,na.rm=T) |
 |
|
# 열별 총합 apply(df[,c(2,3)],2,sum) apply(df[,c(2,3)],2,sum,na.rm=T) |
 |
|
# 행의 합 rowSums(df[,c(2,3)]) rowSums(df[,c(2,3)],na.rm=T) |
 |
|
# 열의 합 colSums(df[,c(2,3)]) colSums(df[,c(2,3)],na.rm=T) |
 |
|
# 행, 열의 평균 rowMeans(df[,c(2,3)],na.rm=T) colMeans(df[,c(2,3)],na.rm=T) |
 |
2. lapply
- 벡터, 리스트, 데이터프레임에 함수를 적용하고 그 결과를 리스트로 리턴하는 함수
|
x <- list(a=1:3,b=4:6)  |
|
|
# 키 별로 직접 계산 sum(x$a) |
 |
|
# 키 별로 따로 계산 lapply(x, sum) |
 |
|
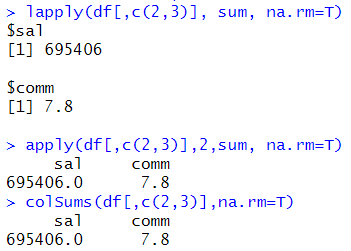
# 열을 기준을 계산 lapply(df[,c(2,3)], sum, na.rm=T) apply(df[,c(2,3)],2,sum, na.rm=T) colSums(df[,c(2,3)],na.rm=T) |
 |
|
# 계산값 인덱싱 colSums(df[,c(2,3)],na.rm=T)[1] colSums(df[,c(2,3)],na.rm=T)[2] |
 |
3. sapply
- 벡터, 리스트, 데이터프레임에 함수를 적용하고 그 결과를 벡터로 리턴하는 함수
|
x<-sapply(df[,c(2,3)],sum,na.rm=T)  |
|
| sapply(df[,c(2,3)],sum,na.rm=T) |  |
|
# 벡터 형식을 데이터 프레임으로 형변환 as.data.frame(x) # 잘못된 방식 |
 |
|
# 벡터 형식을 데이터 프레임으로 형변환 # 벡터 -> 매트릭스 matrix(x) matrix(x,ncol=2)
# 매트릭스 -> 데이터프레임 y <- data.frame(matrix(x,ncol=2)) names(y) <- c("sql","python") mode(y) str(y) |
  |
4. tapply
- 벡터, 데이터프레임에 저장된 데이터를 주어진 기준에 따라 그룹으로 묶은 뒤 그룹 함수를 적용하고 그 결과를 array형식으로 리턴하는 함수
|
# 세로 방향 aggregate(SALARY ~ DEPARTMENT_ID+JOB_ID, emp, sum) |
 |
|
# 가로 방향 tapply(emp$SALARY,list(emp$DEPARTMENT_ID,emp$JOB_ID),sum) |
 |
|
# NA값을 0으로 바꿔서 출력 tapply(emp$SALARY,list(emp$DEPARTMENT_ID,emp$JOB_ID),sum,default=0)
tapply(emp$SALARY,data.frame(emp$DEPARTMENT_ID,emp$JOB_ID),sum,default=0) |
 |
'컴퓨터 > R' 카테고리의 다른 글
| R - 반복문 (0) | 2020.04.14 |
|---|---|
| R - 조건 제어문 (0) | 2020.04.13 |
| R - 그룹 함수 (0) | 2020.04.13 |
| R - 중복 제거 / 정렬 (0) | 2020.04.13 |
| R - 함수 ③ 날짜 함수 (0) | 2020.04.10 |