
grep
: 동일한 문자열을 벡터에서 찾아서 인덱스 번호를 리턴하는 함수
기본 사용법
|
# 해당 인덱스 번호로 출력 text <- c('a','ab','acb','accb','acccb','accccb') grep('a',text) grep('ab',text) grep('acb',text) grep('c',text) |
 |
|
# 해당 값으로 출력 grep('acb',text, value=T) |
 |
정규표현식 사용
|
text <- c('h', 'ha', 'hap', 'hapy', 'happ', 'happy', 'happpy', 'abcd', 'cdab', 'cabd', 'c abd') |
|
|
# * : 적어도 0번이상 grep('hap*y',text, value=T) |
 |
|
# + : 적어도 1번이상 grep('hap+y',text, value=T) |
 |
|
# ? : 0번 또는 1번 grep('hap?y',text, value=T) |
 |
|
# {n} : n번 매칭하면 찾는다. grep('hap{2}y',text, value=T) |
 |
|
# {n,} : n번 이상 매칭하면 찾는다. grep('hap{2,}y',text, value=T) |
 |
|
# {n,m} : n번부터 m번까지 매칭하면 찾는다. grep('hap{1,3}y',text, value=T) |
 |
|
# ^ : 시작되는 문자를 찾는다. grep('^ab',text,value=T) |
 |
|
# $ : 끝나는 문자를 찾는다. grep('ab$',text,value=T) |
 |
|
# \\b : 시작되는 문자를 찾는데 빈문자열 뒤에 식작되는 문자도 찾는다. grep('\\bab',text,value=T) |
 |
|
# [...] : 리스트 안에 있는 문자 매칭 grep('ab[c,d,e]',text,value=T) |
 |
|
# [n-m] : n부터 m까지 문자 매칭 grep('ab[c-e]',text,value=T) |
 |
|
# \\^ : '^' 문자 매칭 grep('\\^',text,value=T) |
 |
|
# \\$ : '$' 문자 매칭 grep('\\$',text,value=T) |
 |
|
text <- c("sql", "SQL", "Sql100", "PYTHON", "Python", "python", "R", "r", "r0", "R#", "100", "*", "$", "^", "*100") |
|
|
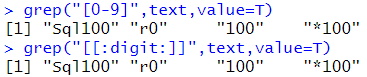
# 숫자를 찾는다. grep("[0-9]",text,value=T) grep("[[:digit:]]",text,value=T) |
 |
|
# 대문자를 찾는다. grep("[[:upper:]]",text,value=T) |
 |
|
# 소문자를 찾는다. grep("[[:lower:]]",text,value=T) |
 |
|
# 문자를 찾는다.(특수문자는 제외) grep("[[:alpha:]]",text,value=T) |
 |
|
# 문자와 숫자를 찾는다.(특수문자는 제외) grep("[[:alnum:]]",text,value=T) |
 |
|
# 특수 문자를 찾는다. grep("[[:punct:]]",text,value=T) |
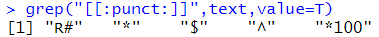 |
|
# 대소문자 구분 없이 찾고 싶을때 grep("SQL",text,value=T,ignore.case=T) |
 |
|
# 두가지 패턴 찾기 grep("Steven",emp$FIRST_NAME,value=T) grep("Stephen",emp$FIRST_NAME,value=T) grep("Ste(v|ph)en",emp$FIRST_NAME,value=T) |
 |
|
# 활용 emp[grep("Ste(v|ph)en",emp$FIRST_NAME,value=F),] |
 |
'컴퓨터 > R' 카테고리의 다른 글
| R - 시각화 ① pie chart, bar graph (0) | 2020.04.20 |
|---|---|
| R - 분할표 만들기 (0) | 2020.04.20 |
| R - melt / dcast (0) | 2020.04.17 |
| R - sqldf (0) | 2020.04.17 |
| R - dplyr 라이브러리 ② summarise , group_by (0) | 2020.04.17 |