
KoNLPy
https://konlpy-ko.readthedocs.io/ko/v0.4.3/
KoNLPy: 파이썬 한국어 NLP — KoNLPy 0.4.3 documentation
KoNLPy: 파이썬 한국어 NLP KoNLPy(“코엔엘파이”라고 읽습니다)는 한국어 정보처리를 위한 파이썬 패키지입니다. 설치법은 이 곳을 참고해주세요. NLP를 처음 시작하시는 분들은 시작하기 에서 가볍게 기본 지식을 습득할 수 있으며, KoNLPy의 사용법 가이드는 사용하기, 각 모듈의 상세사항은 API 문서에서 보실 수 있습니다. >>> from konlpy.tag import Kkma >>> from konlpy.utils import pprin
konlpy-ko.readthedocs.io
KoNLPy는 한국어 정보처리를 위한 파이썬 패키지이다.
아나콘다 프롬프트 창에서
pip install konlpy
로 설치를 진행한다.
!!! 주의 !!!
JAVA 1.7이상 버전이 미리 설치되어 있어야 한다.
# KoNLPy Okt 임포트
from konlpy.tag import Okt
txt = "아버지가방에들어가신다."
일때
# 인스턴스 생성 okt = Okt() | |
# 형태소 분석 okt.pos(txt) okt.pos("이것도 되나욬ㅋㅋㅋㅋ") |   |
# norm = True : 품사 태깅(기본값 False) okt.pos("이것도 되나욬ㅋㅋㅋㅋ",norm = True) |  |
# stem=True : 원형 글자로 바꿔준다. (기본값 False) okt.pos("이것도 되나욬ㅋㅋㅋㅋ",norm = True,stem=True) |  |
# 텍스트를 형태소 단위로 나눈다. okt.morphs(txt) | 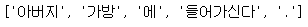 |
# 텍스트에서 명사만 추출 okt.nouns(txt) |  |
# 텍스트에 어절을 추출 okt.phrases(txt) |  |
# KoNLPy Kkma 임포트
from konlpy.tag import Kkma
# 인스턴스 생성 kkma = Kkma() | |
# 형태소 분석 kkma.pos(txt) |   |
# 텍스트를 형태소 단위로 나눈다. kkma.morphs(txt) |  |
# 텍스트에서 명사만 추출 kkma.nouns(txt) |  |
# 텍스트에서 문장을 분석 kkma.sentences(txt) |  |
말뭉치
: 문장을 하나로 모으는것
from konlpy.corpus import kolaw
from konlpy.tag import Okt
import nltk
# 말뭉치로 텍스트 읽어들이기
doc_ko = kolaw.open("애국가.txt").read() |  |
# 말뭉치에서 단어 추출 okt = Okt() |  |
# 다시 단어들을 문장으로 만들기 ko = nltk.Text(token_ko) |  |
# 중복되는 단어 제거 len(ko.tokens) |  |
# 단어들의 빈도수 체크 ko.vocab() |  |
# 그래프로 확인 plt.figure(figsize=(12,7)) |  |
# 불용어 처리 stopword = ['이','저','데'] |  |
# 연관있는 단어들을 뽑아줌 ko = nltk.Text(ko) |  |
| ko_vocab = ko.vocab() # 상위 30개만 뽑아내기 / 리스트 모양으로 바뀜 data = ko.vocab().most_common(30) data |  |
# wordcloud로 만들기 wordcloud = WordCloud(font_path='C:\windows/fonts/malgun.ttf', |  |
'컴퓨터 > 파이썬' 카테고리의 다른 글
| 파이썬(Python) - 스크래핑 ④ selenium을 이용한 크롤링 (0) | 2020.04.05 |
|---|---|
| 파이썬(Python) - 크롤링 연습 ② 국민 청원 청원 목록 수집(추천순) (2) | 2020.04.03 |
| 파이썬(Python) - 크롤링 연습 ① 사람인 빅데이터 채용 조건 수집 (0) | 2020.04.01 |
| 파이썬(Python) - 스크래핑 ③ JSON을 이용한 크롤링 (0) | 2020.03.31 |
| 파이썬(Python) - 예외사항 처리 (0) | 2020.03.30 |